✅派聪明环境搭建指南(新人必看)Java 17、MySQL、Elasticsearch、Redis、MinIO、Kafka
一、安装 Java 17
二哥的 macOS 安装方式
我是直接通过 warp 这个终端工具 agent 安装的,只不过没有创建符号连接,因为我电脑上安装有其他 JDK 版本。
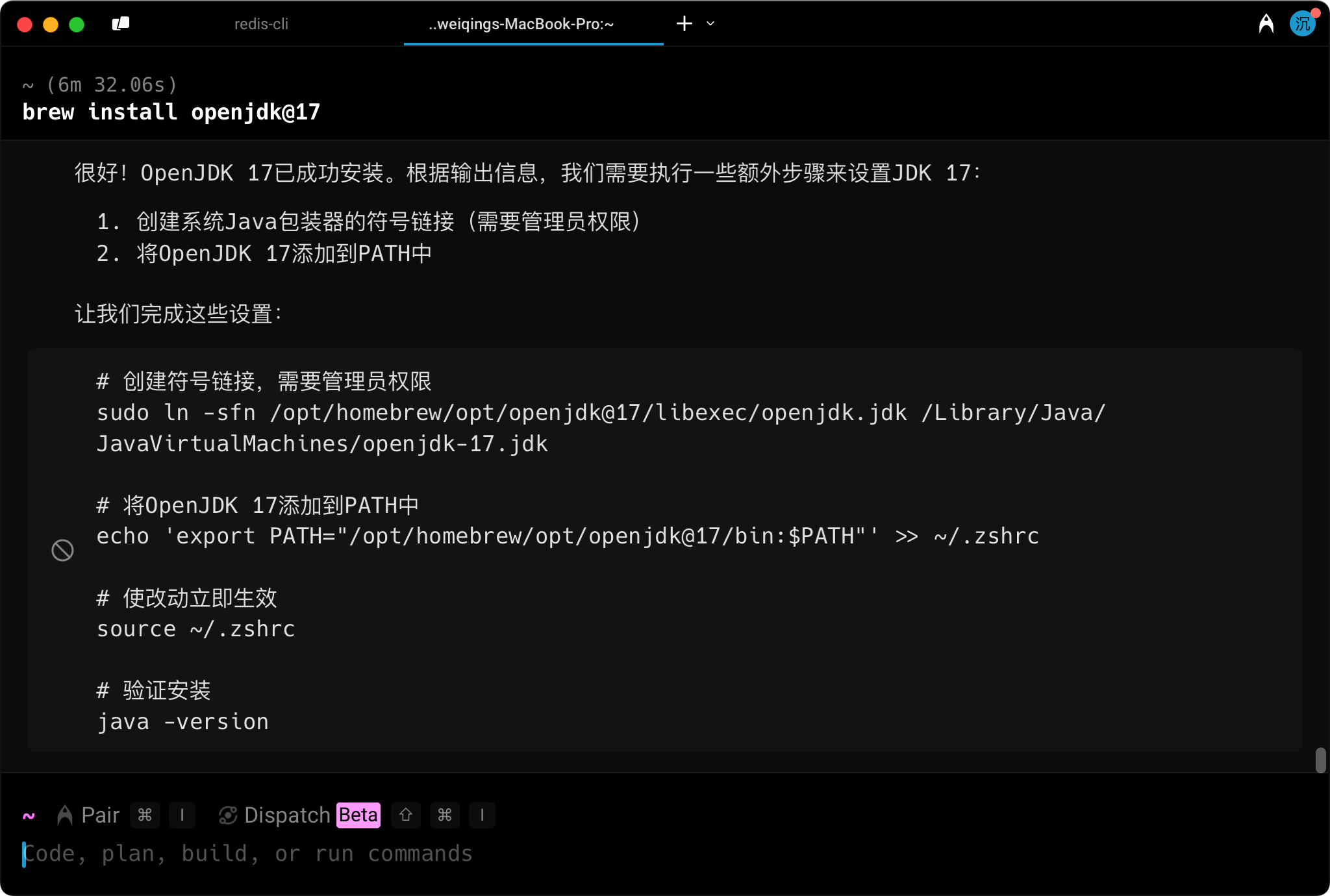
我安装了 jenv,可以在 macOS 上管理多个版本的 JDK,我在这个帖子:https://javabetter.cn/overview/jdk-install-config.html#_03%E3%80%81macos-%E5%AE%89%E8%A3%85-jdk 里也有讲,需要的球友可以去看一眼。
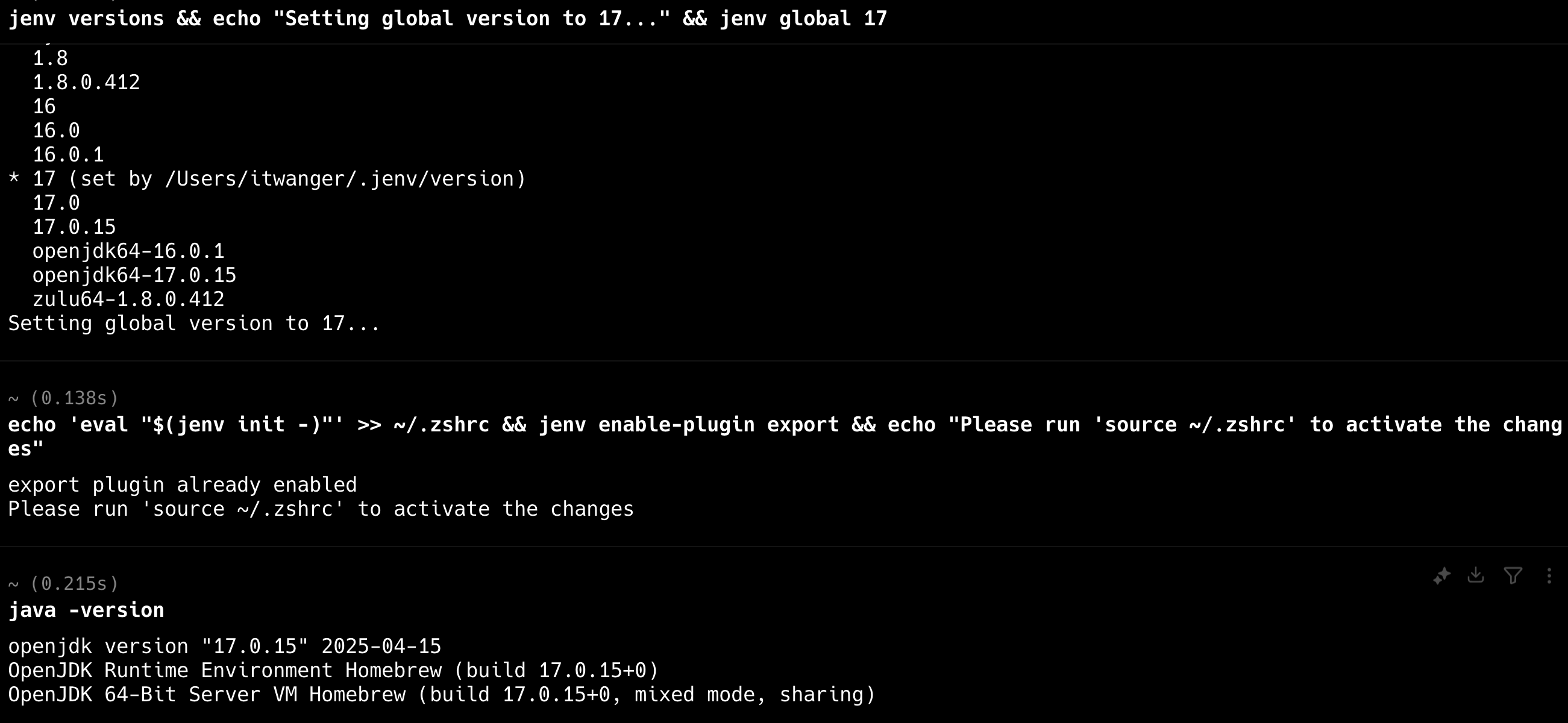
可以执行 jenv add /opt/homebrew/opt/openjdk@17把 JDK17 添加到 jenv 中,然后设置 JDK17 为全局的默认版本 jenv versions && echo "Setting global version to 17..." && jenv global 17,配置成功的话,可以通过 java -version确认。
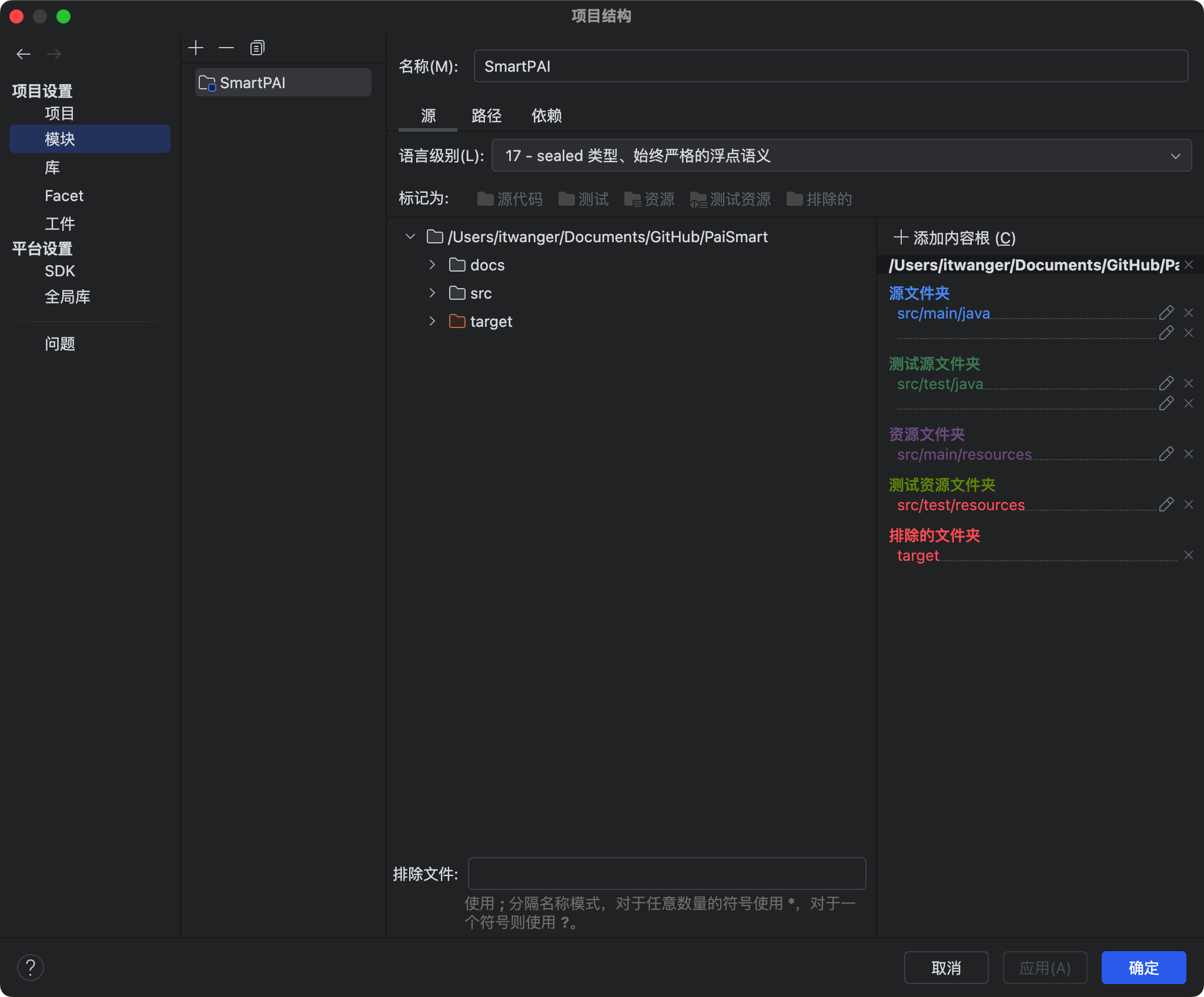
然后在 IntelliJ IDEA 中把 paismart 项目的编译版本设置为 JDK17
Windows 的话,可以直接下载安装包,然后在 PATH 命令中设置路径就好了,我这里就不再截图,参考这个连接:手把手教你在 Windows 和 macOS 下安装 JDK,菜逼也能掌握
Lan 的 macOS 安装步骤
# 使用 Homebrew 安装 OpenJDK 17 brew install openjdk@17 # 创建符号链接以使系统可以找到 java 可执行文件 sudo ln -sfn $(brew --prefix)/opt/openjdk@17/libexec/openjdk.jdk /Library/Java/JavaVirtualMachines/openjdk-17.jdk # 添加到 ~/.zshrc 或 ~/.bash_profile 中 echo 'export PATH="$(brew --prefix)/opt/openjdk@17/bin:$PATH"' >> ~/.zshrc source ~/.zshrc 复制代码
验证安装
java -version 复制代码
应显示类似以下输出:
openjdk version "17.0.x" 2023-xx-xx
OpenJDK Runtime Environment (build 17.0.x+x-xxxx)
OpenJDK 64-Bit Server VM (build 17.0.x+x-xxxx, mixed mode, sharing)
二、安装 MySQL
二哥的安装步骤
我是直接下载的安装包,参考:MySQL 的安装、启动、连接(Windows、macOS 和 Linux)
Lan 的 安装步骤
# 安装 MySQL 8.0 brew install mysql@8.0 # 启动 MySQL 服务 brew services start mysql # 设置 root 密码 mysql_secure_installation 复制代码
在安全设置向导中,设置 root 密码并按照提示完成其他安全设置。
验证安装
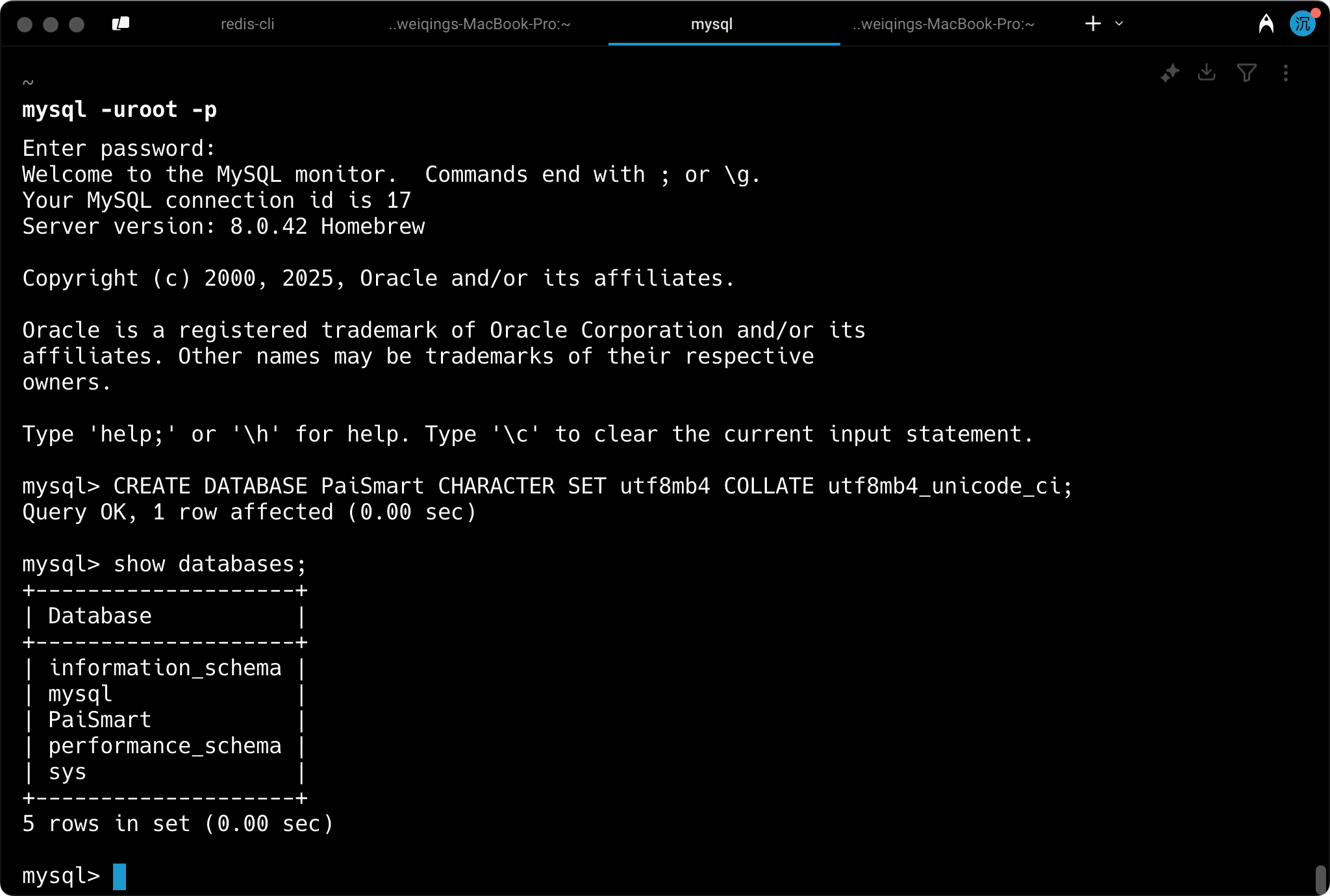
# 使用 root 用户登录 MySQL mysql -uroot -p 复制代码
成功登录后,应该看到 MySQL 命令行界面。
创建数据库和用户
-- 创建数据库 CREATE DATABASE PaiSmart CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; 复制代码
三、安装 Elasticsearch
这个安装的比较复杂,我们单独写了一篇内容,可戳链接直达:ES 8.x 安装

四、安装 Redis
直接看这篇帖子:Redis 的安装,macOS、Windows 和 Linux 里面有详细讲安装方式。
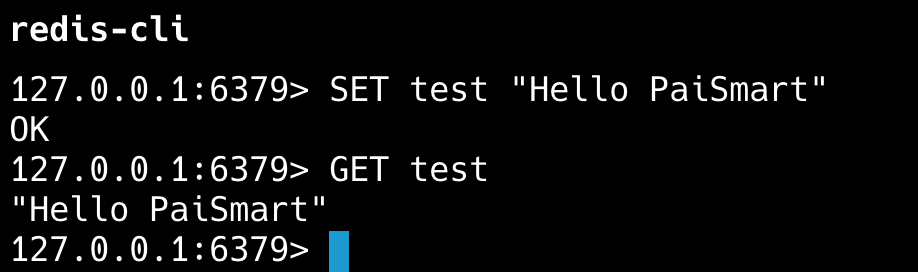
安装完成后,可以通过 redis-cli测试一下。# 连接到 Redis redis-cli # 测试 Redis 是否正常工作 SET test "Hello PaiSmart" GET test 复制代码
应该能看到 Redis 返回 “Hello PaiSmart”。
五、安装 MinIO
关于 minio 我之前在写编程喵的时候,写过一篇教程《Spring Boot 整合 MinIO 自建对象存储服务》,可以直接通过下面的内容查看,里面也有 MinIO 的介绍和在 Linux 上的安装部署,以及和 Spring Boot 的前后打通。
编程喵的教程和密码获取方式在星球第一个置顶帖【球友必看】里:https://t.zsxq.com/91hPx
当然了,也可以不看,直接按照下面的步骤来。
二哥的安装步骤
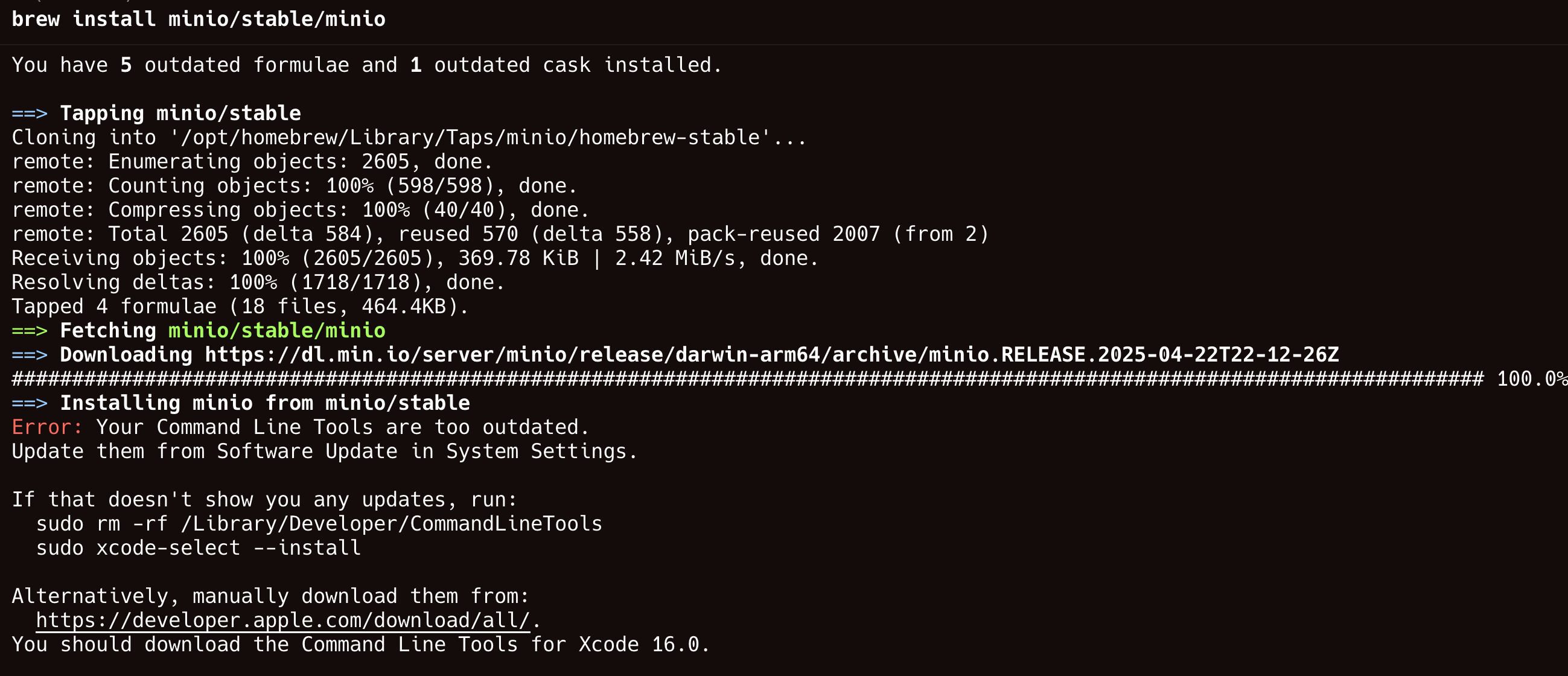
我一开始是通过 Lan 的 homebrew 安装的:# 安装 MinIO brew install minio/stable/minio # 安装 MinIO 客户端 brew install minio/stable/mc 复制代码
我本机提示命令行工具过时了,所以安装失败了。但我又不想升级系统,所以咱们需要换一个方法。
访问这个链接:https://dl.min.io/server/minio/release/
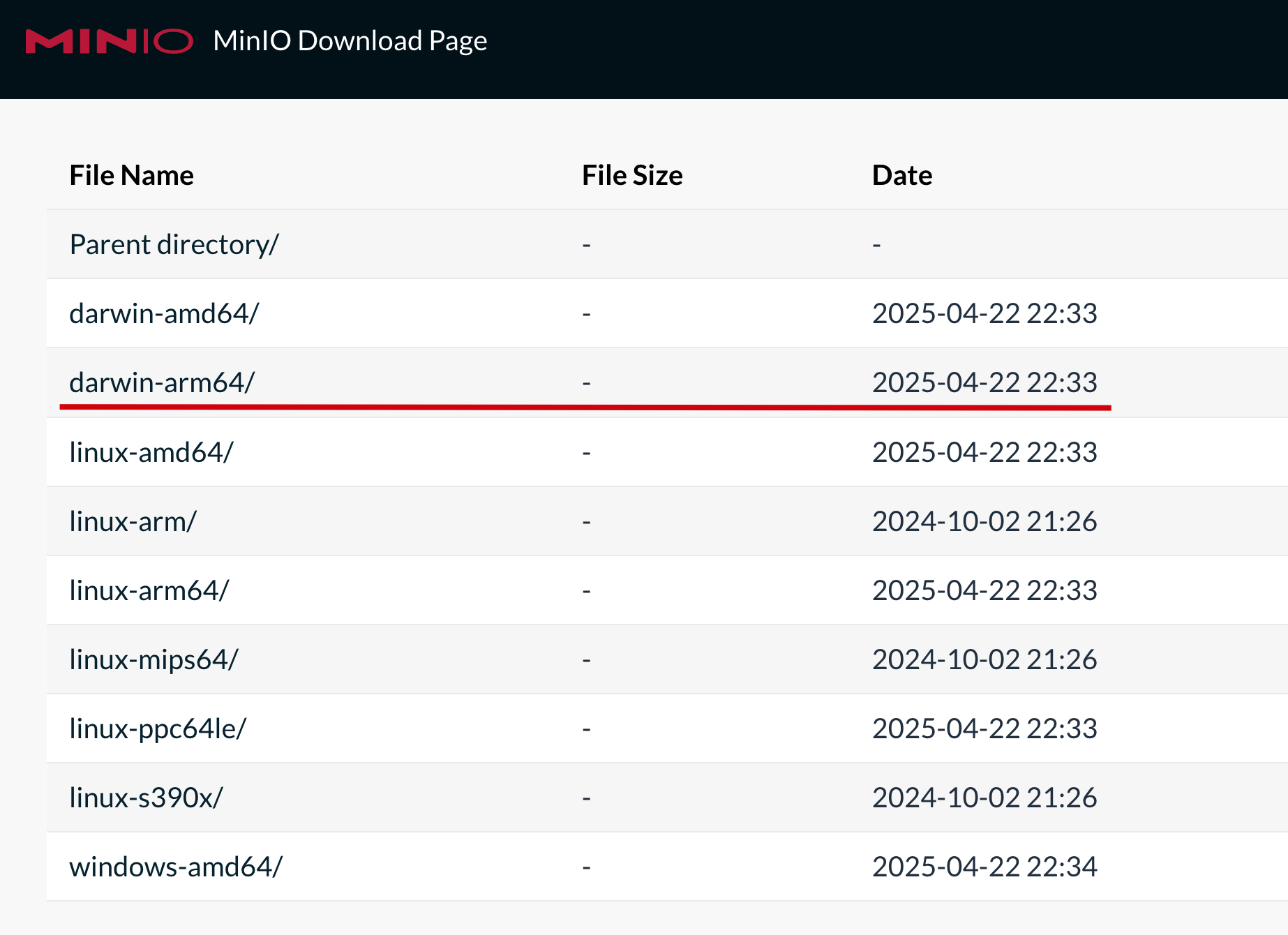
根据自己的系统选择对应的版本,比如说我是 Apple 芯片就选第二个,Windows 就选倒数第一个。下载完成后,macOS 需要给它执行权限。
执行 chmod +x minio,然后为 MinIO 创建一个数据目录 data,之后执行 ./minio server data/就可以启动了。
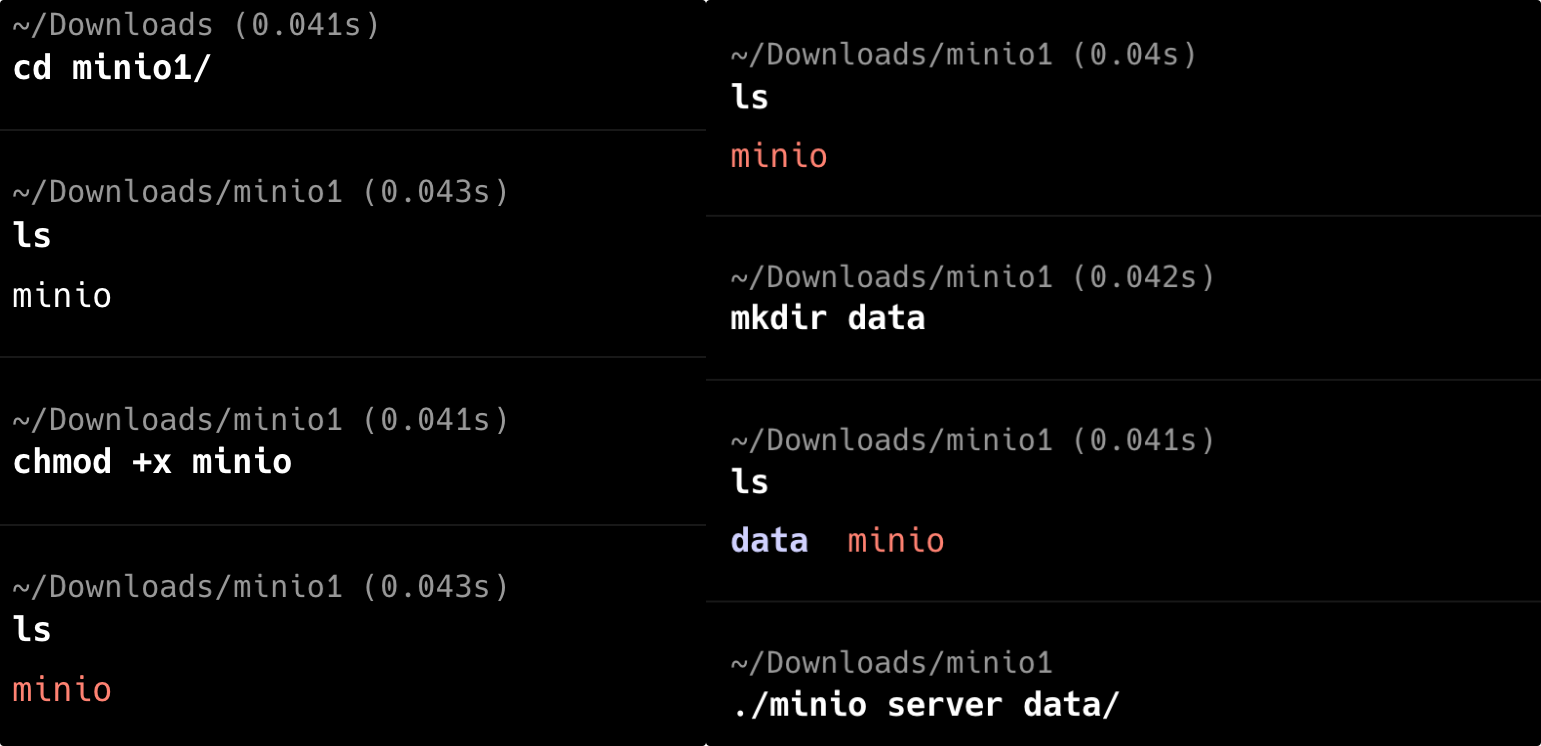
Windows 的话,下载后的就直接是 exe 文件,可以直接执行,当然了,也要记得创建数据目录。如果一切正常的话,应该会输出以下信息,
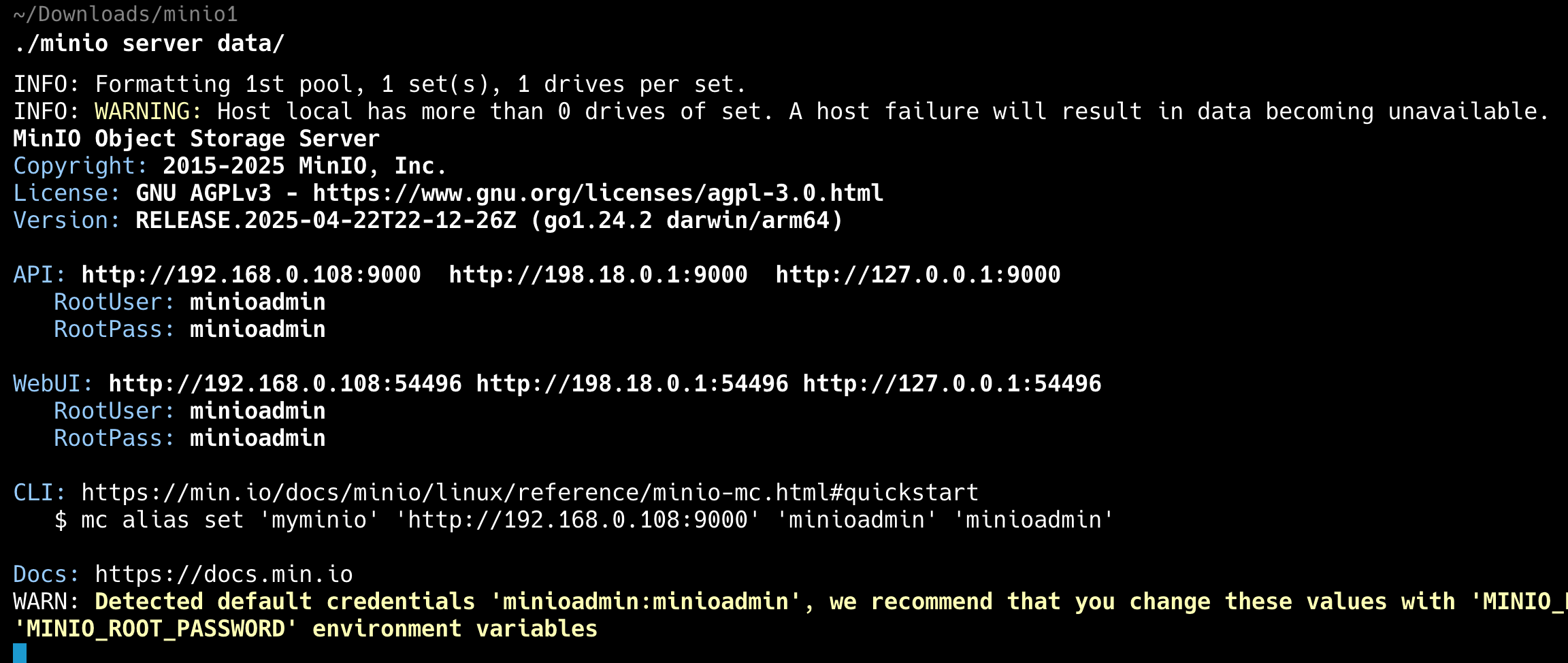
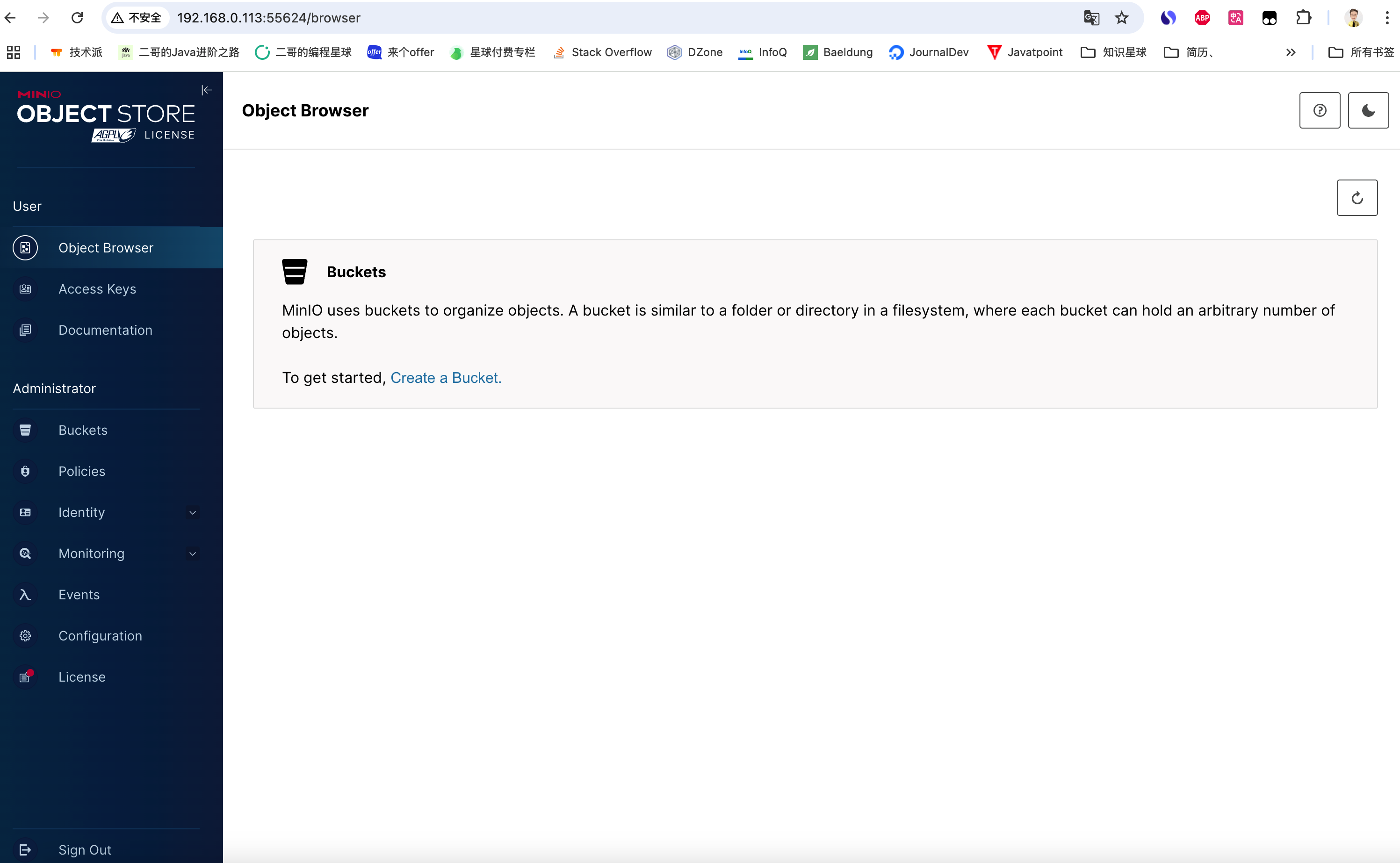
完事直接点击 webui 的访问地址 http://192.168.0.113:55624 启动。注意这个端口号是会变化的,看自己的控制台就好了。

输入用户名和密码 minioadmin,就可以看到 MinIO 的管理端主页了。
Lan 的安装步骤
# 创建数据目录 mkdir -p ~/minio/data 复制代码# 设置环境变量 export MINIO_ROOT_USER=minioadmin export MINIO_ROOT_PASSWORD=minioadmin # 启动 MinIO 服务 minio server ~/minio/data --console-address ":9001" 复制代码
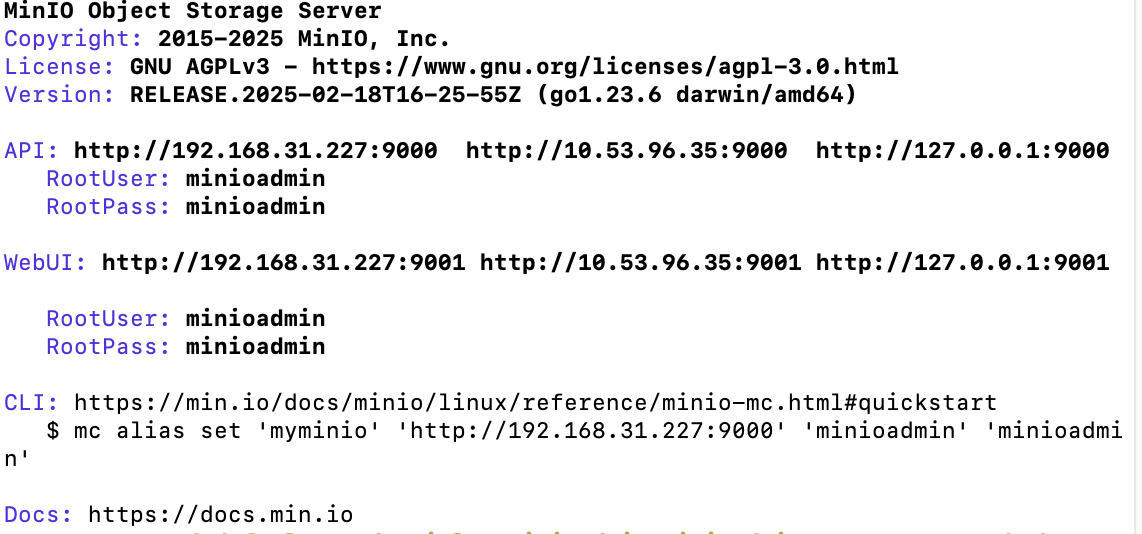
启动后查看日志中 API 地址访问 MinIO 控制台:http://192.168.31.227:9000
使用凭据登录:
- 用户名:minioadmin
- 密码:minioadmin
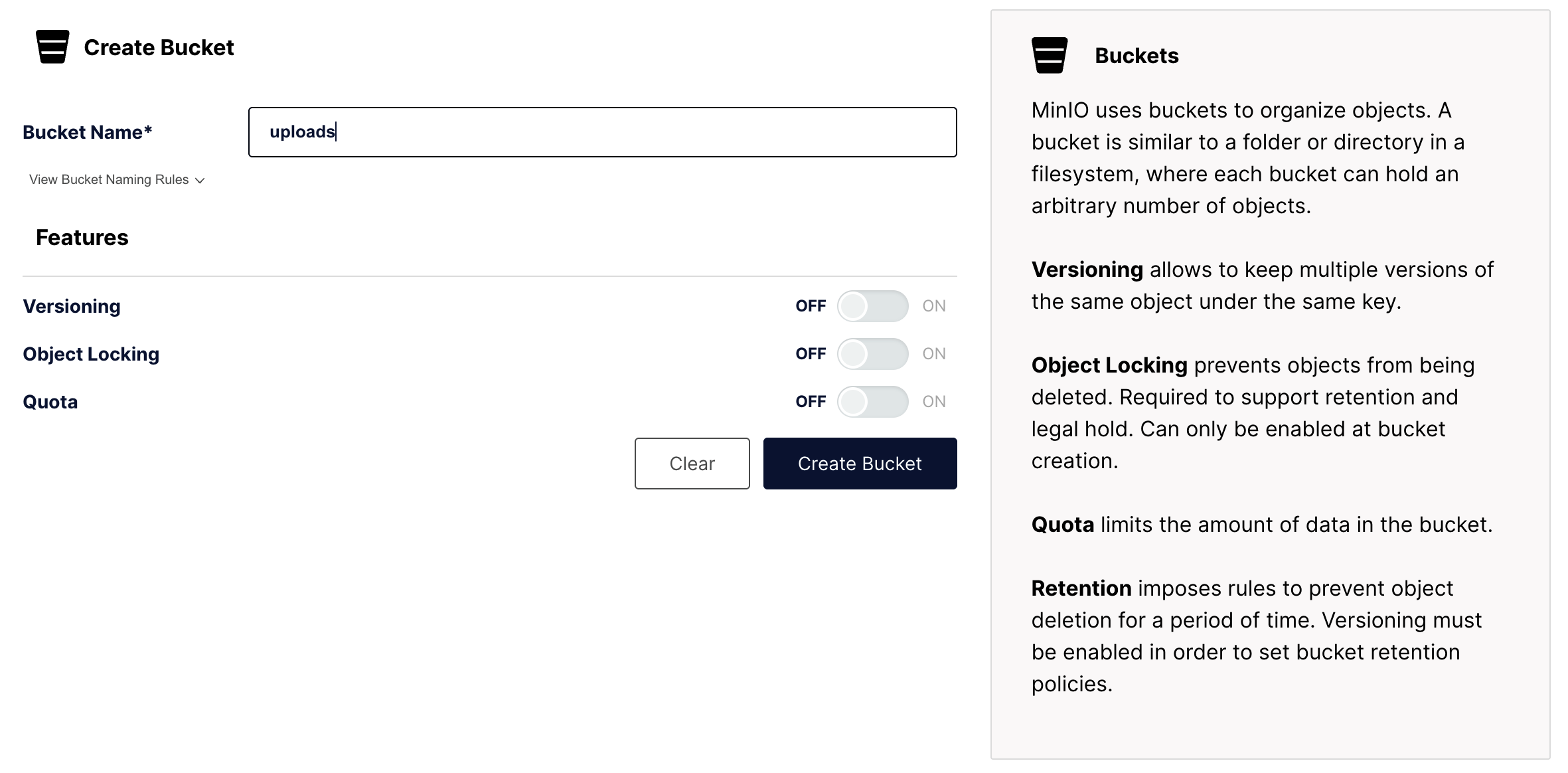
创建 MinIO 的 Bucket
MinIO 中的 Bucket(桶) 是对象存储的核心概念之一,它相当于传统文件系统中的“文件夹”或“目录”,是存储对象(Object)的容器。
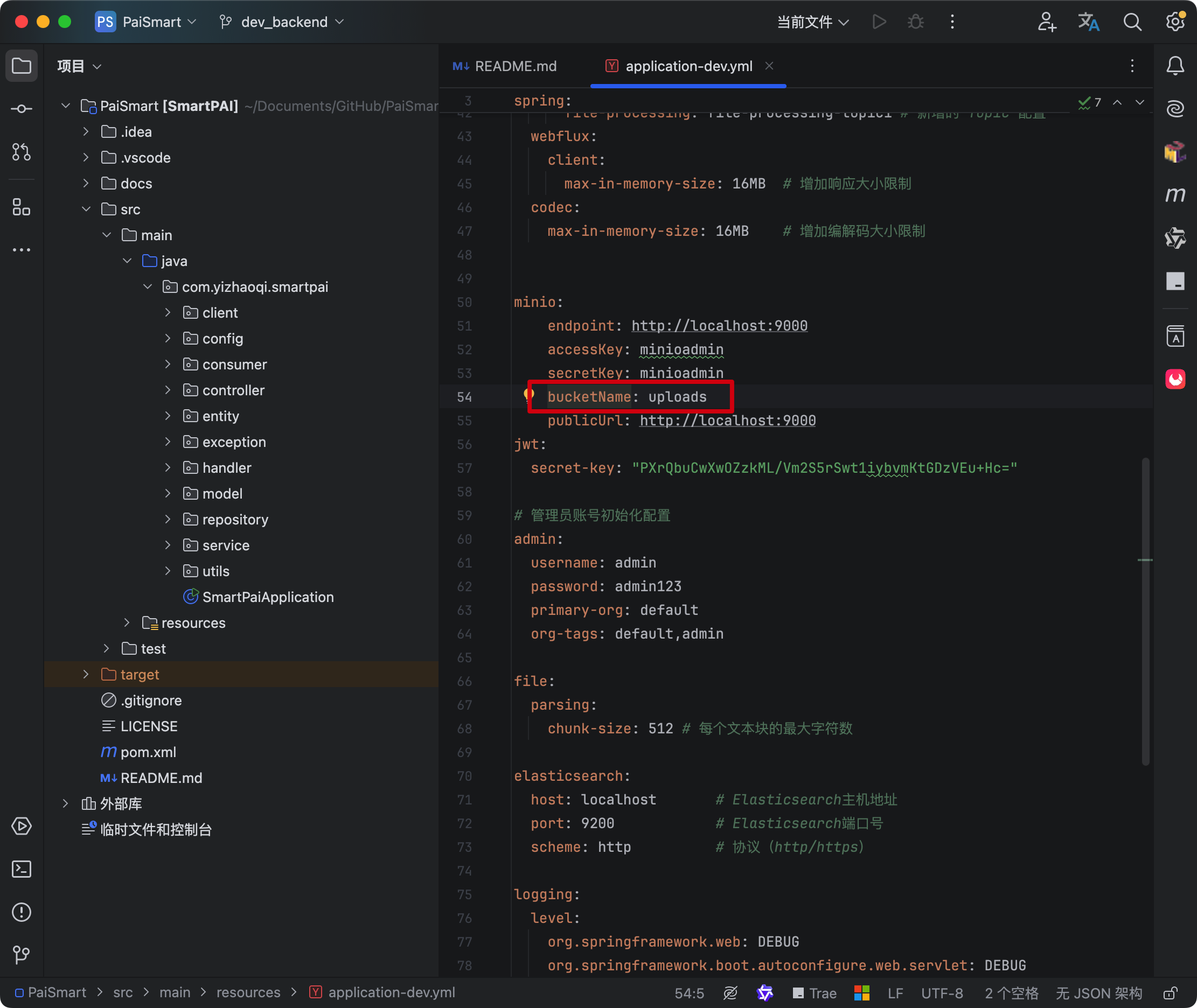
我们可以创建一个 uploads 的桶,它的名字和 yml 配置文件中 bucketName 相同就可以了。
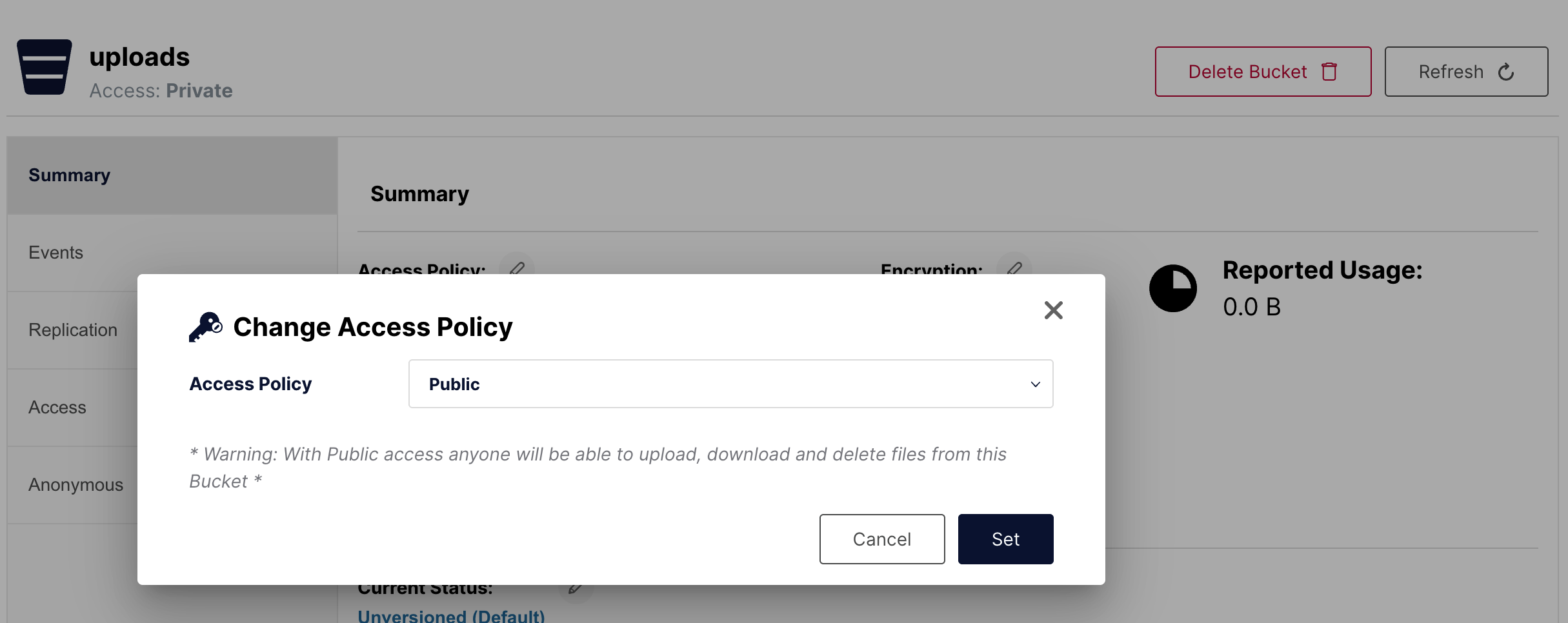
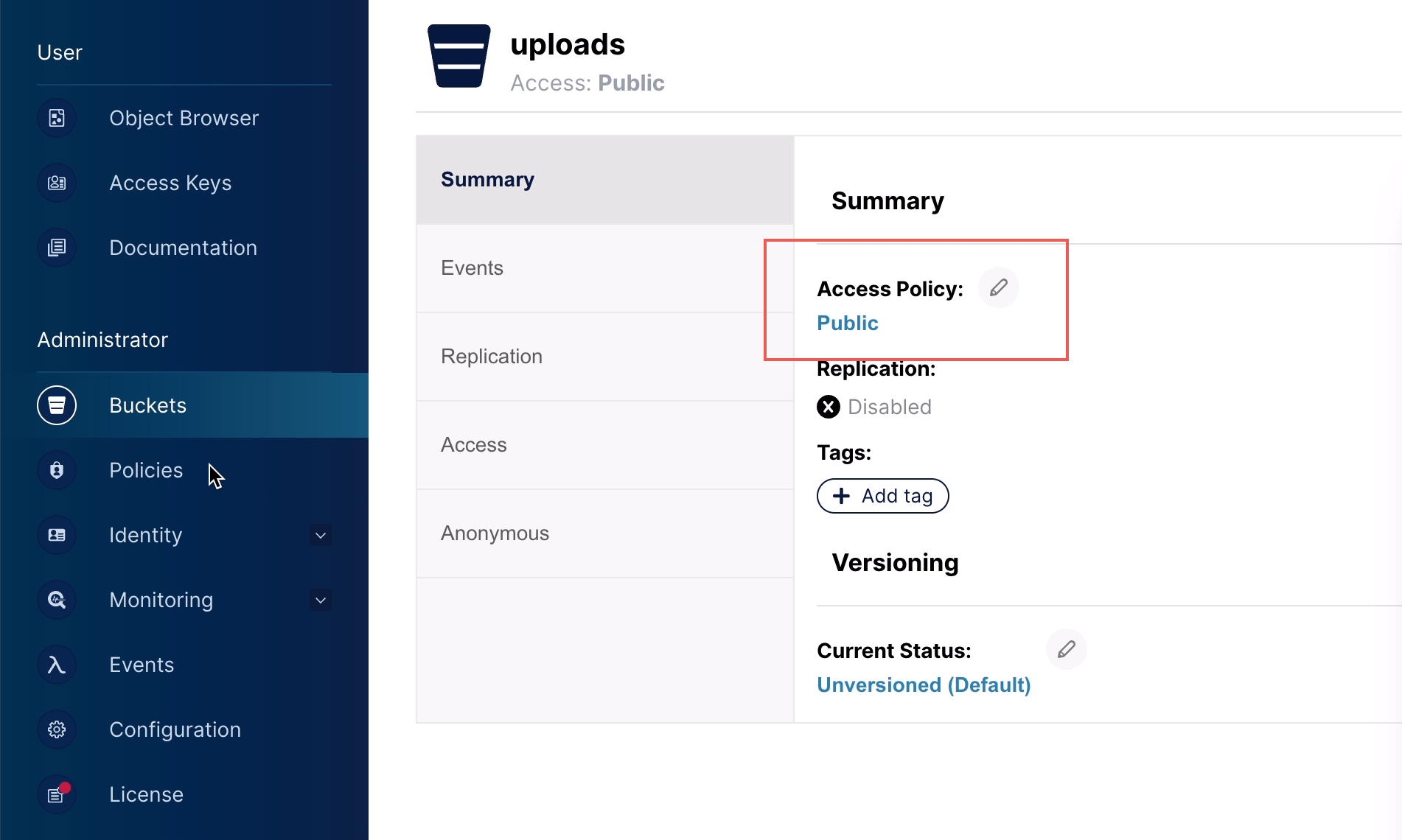
权限设置为 Public
六、安装 Kafka
Kafka 是一个消息中间件,最初由 LinkedIn 开发,后来成为 Apache 的开源项目,主打一个高吞吐、低延迟。
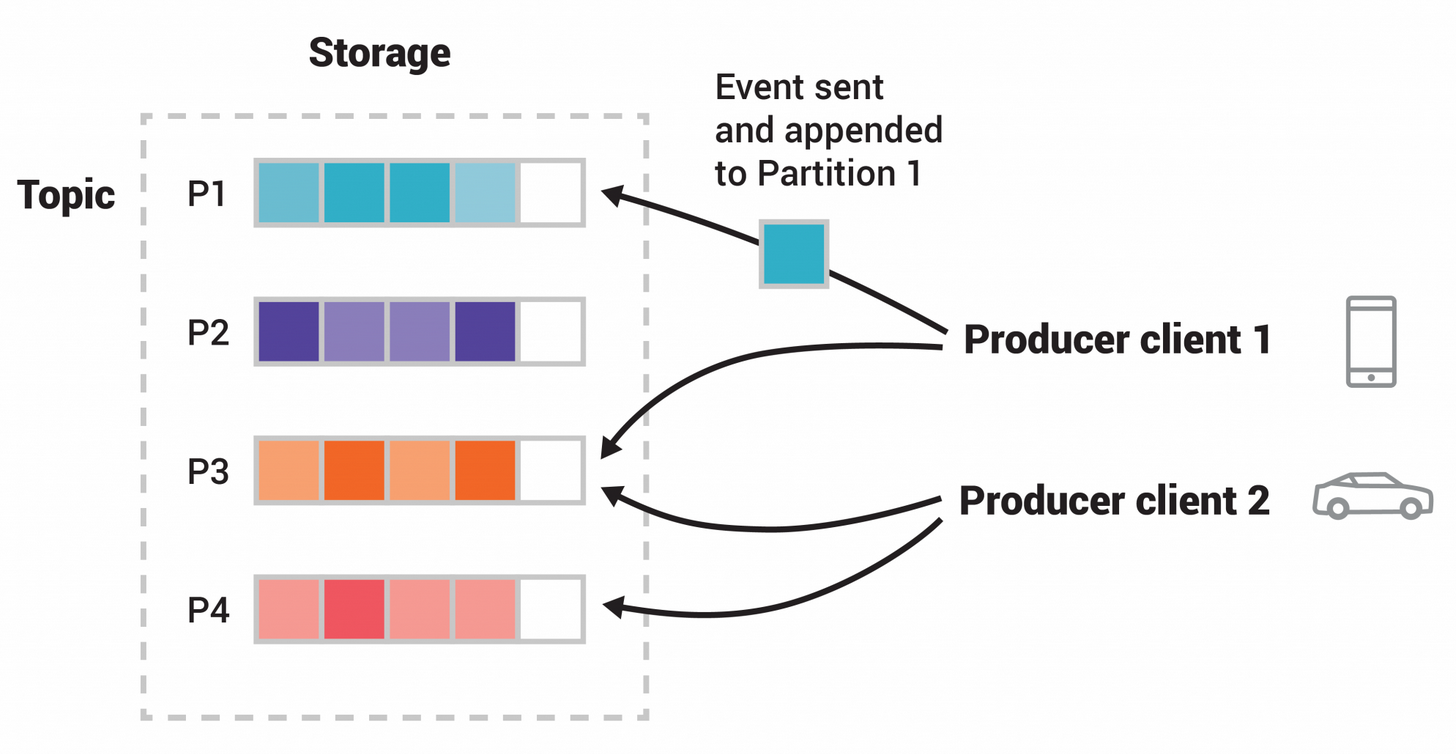
派聪明安装的是 Kafka 3.9 版本,支持 KRaft 模式,不再必须 zookeeper。相当于说以后大小事宜都由我 Kafka 来决定,不再需要 zookeeper 这个外援了。
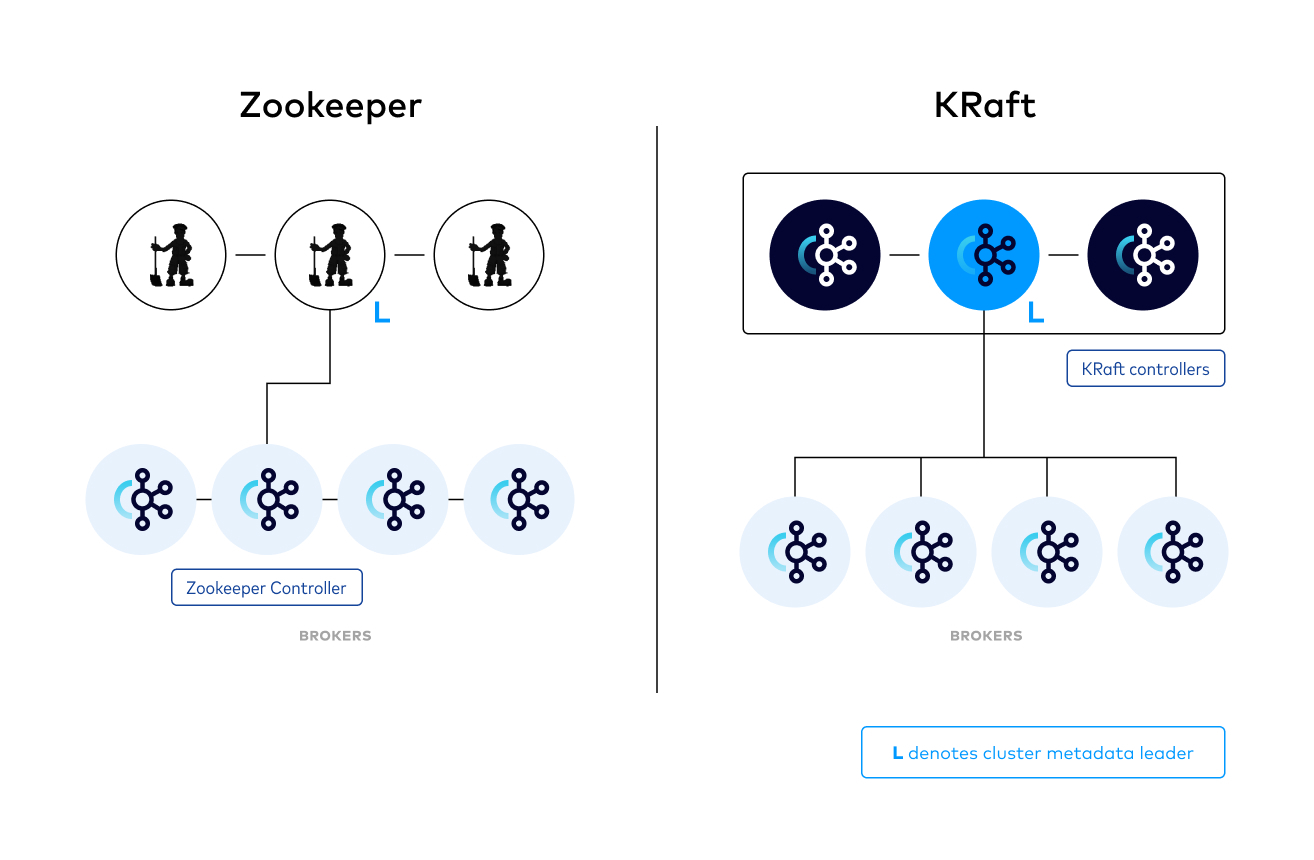
下载 Kafka
可以通过官网直接下载 src 压缩包解压。
也可以直接通过 curl 下载到本地,用 tar 命令解压。curl -O https://downloads.apache.org/kafka/3.9.0/kafka_2.13-3.9.0.tgz 复制代码
配置 KRaft 模式
# 生成集群 ID KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)" echo $KAFKA_CLUSTER_ID # 格式化存储目录 bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties 复制代码
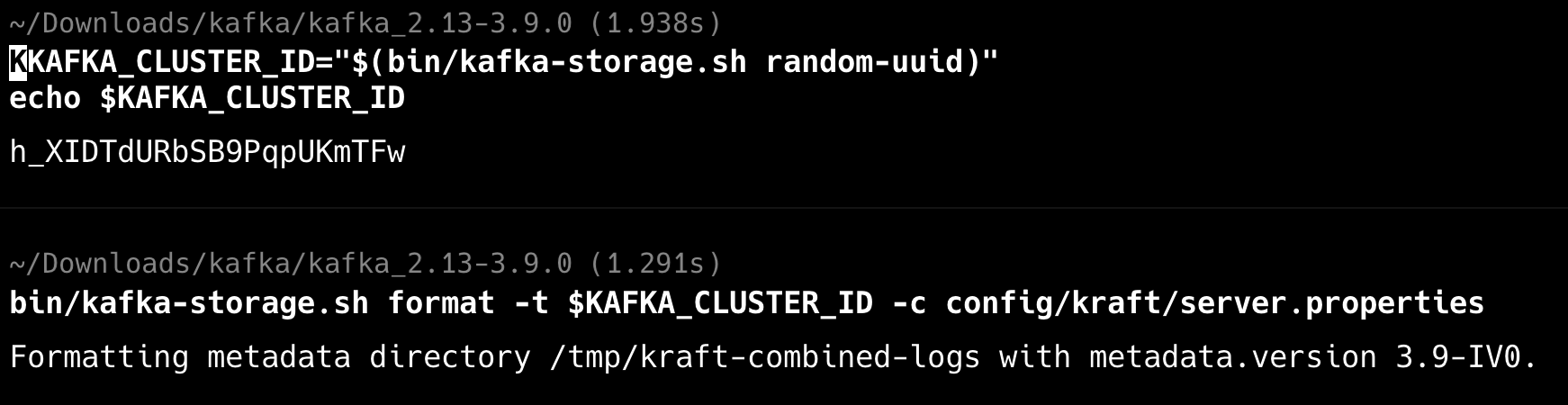
如果这一步出现这个问题 Invalid cluster.id
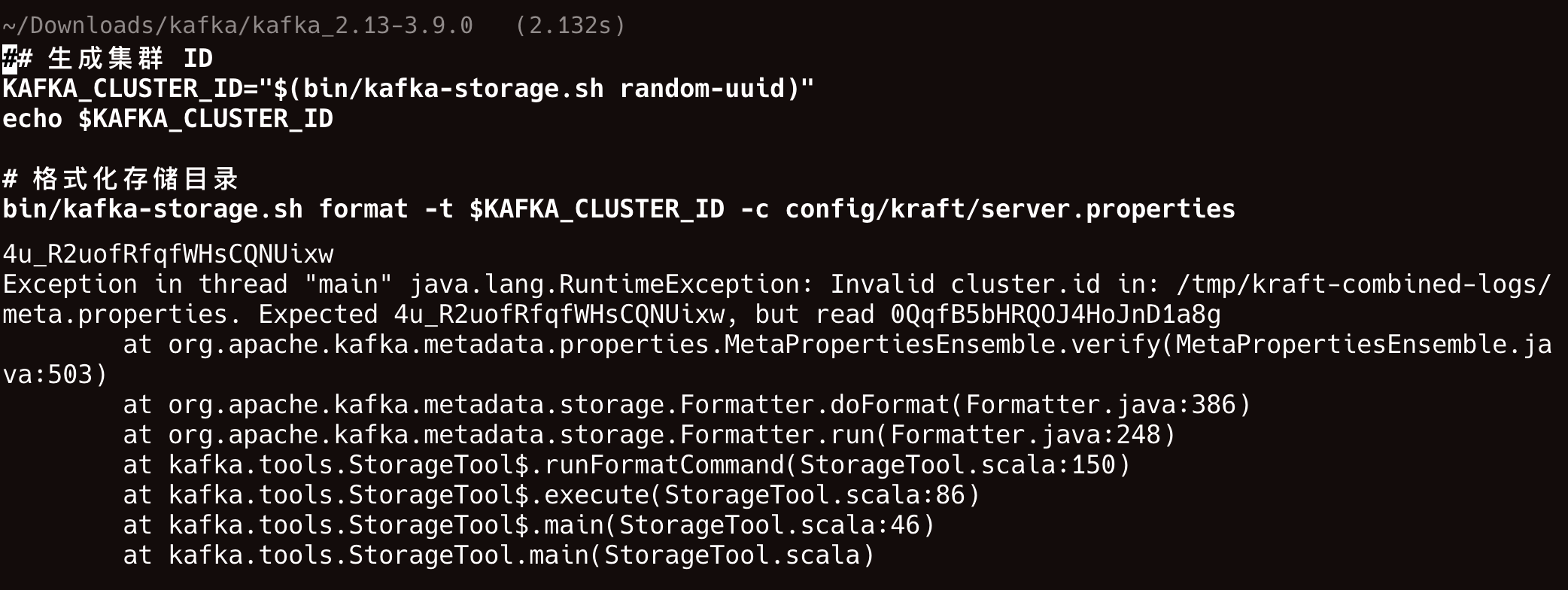
请直接删除 rm -rf /tmp/kraft-combined-logs对应的日志,主要是因为 cluster ID 不匹配。
启动 Kafka 服务器
# 使用 KRaft 模式启动 Kafka bin/kafka-server-start.sh config/kraft/server.properties 复制代码
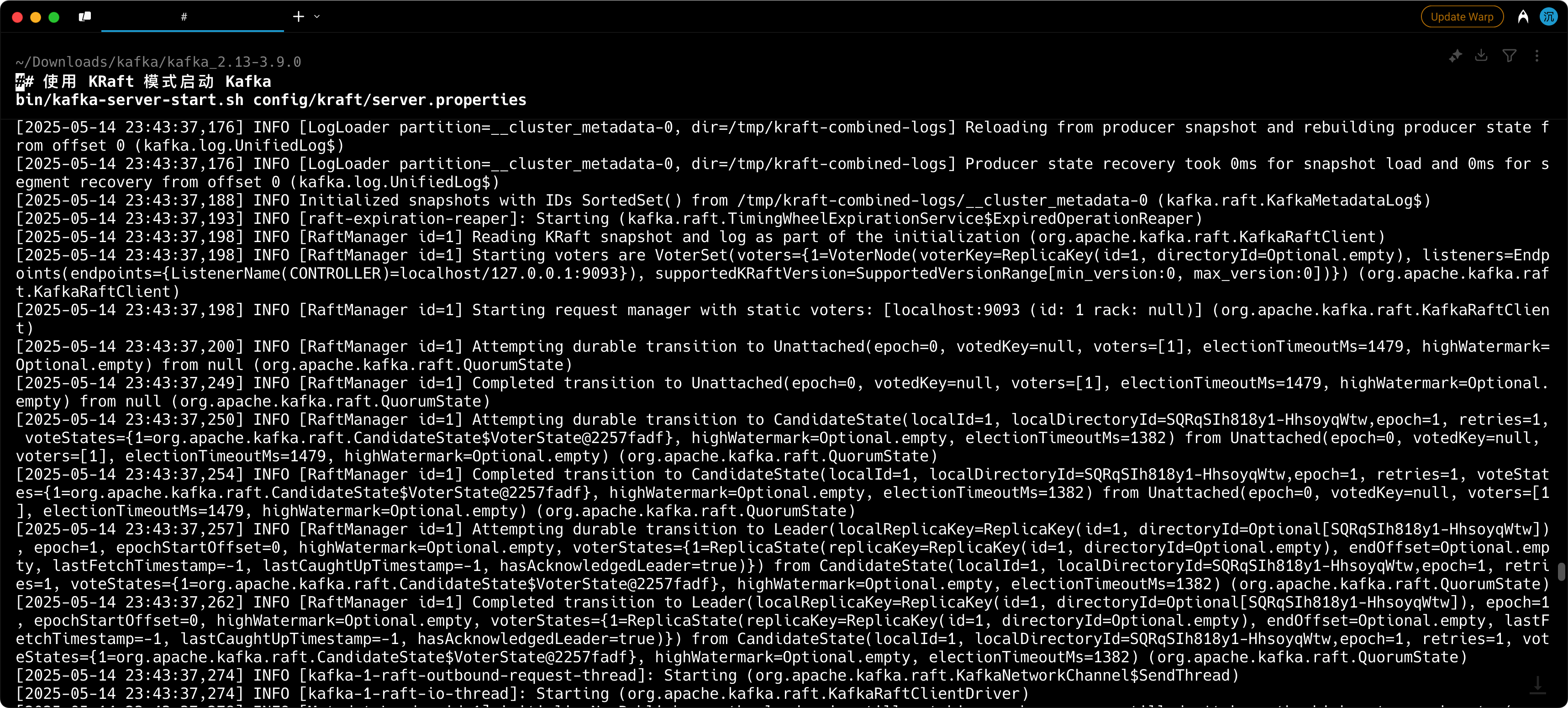
如果你启动过程中出现了这个问题:
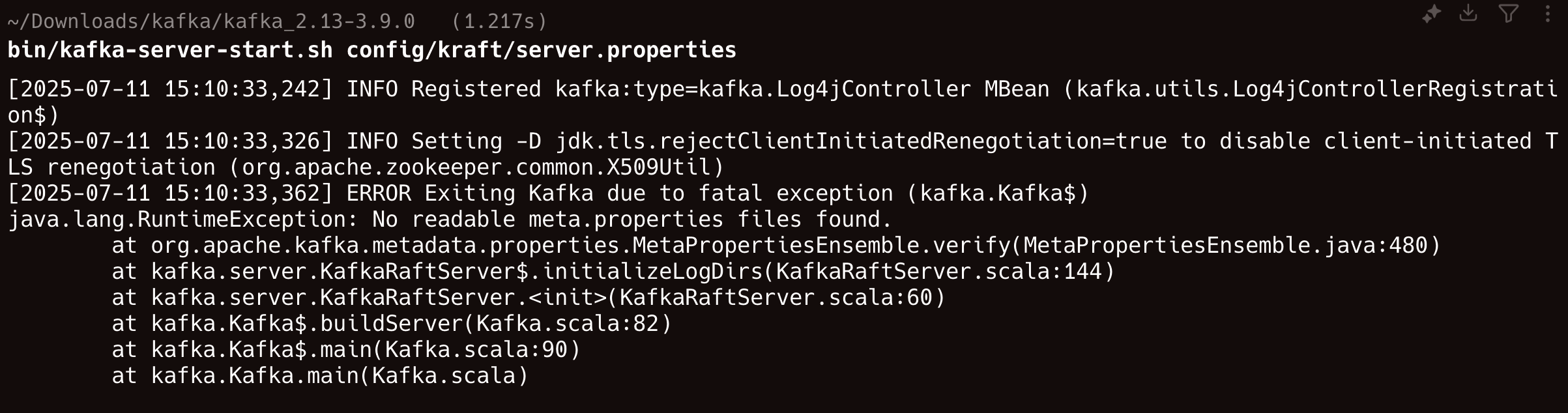
是因为 KRaft 模式需要在启动前初始化,因为我自己装了 wrap 这个智能终端,它可以直接帮我解决掉。
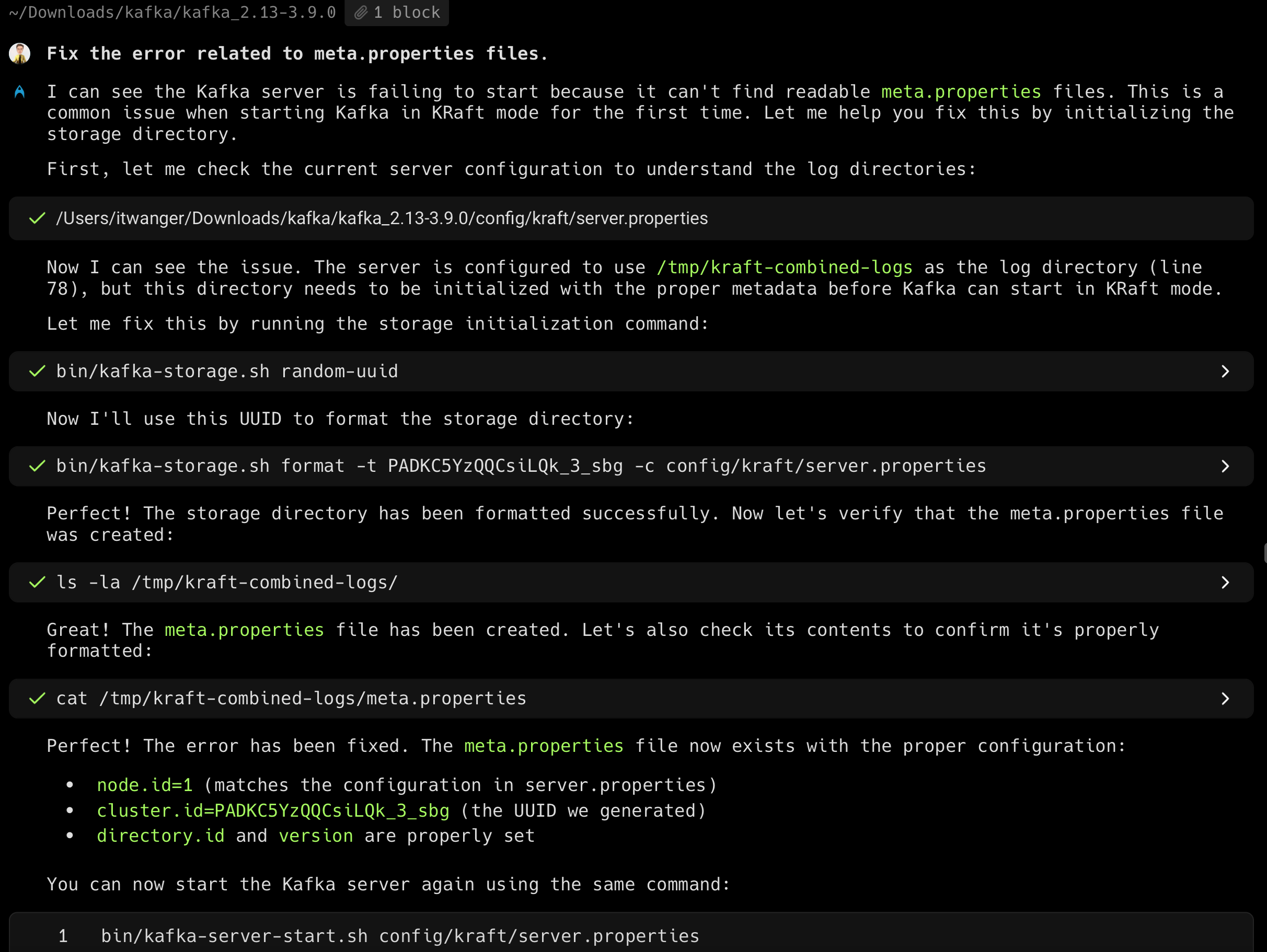
启动 Kafka 脚本
我这里创建了一个脚本,命名为:start-kafka.sh#!/bin/bash # Kafka KRaft模式启动脚本 # 自动处理cluster ID冲突问题 set -e # 遇到错误立即退出 LOG_DIR="/tmp/kraft-combined-logs" CONFIG_FILE="config/kraft/server.properties" echo "=== Kafka KRaft Mode Startup Script ===" echo "当前时间: $(date)" echo "工作目录: $(pwd)" echo # 函数:清理日志目录 cleanup_logs() { if [ -d "$LOG_DIR" ]; then echo "检测到现有日志目录,正在清理..." rm -rf "$LOG_DIR" echo "✓ 日志目录已清理: $LOG_DIR" else echo "日志目录不存在,无需清理" fi } # 函数:生成并格式化存储 format_storage() { echo echo "=== 第1步:生成集群ID ===" KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)" echo "生成的集群ID: $KAFKA_CLUSTER_ID" echo echo "=== 第2步:格式化存储目录 ===" if bin/kafka-storage.sh format -t "$KAFKA_CLUSTER_ID" -c "$CONFIG_FILE"; then echo "✓ 存储格式化成功" return 0 else echo "✗ 存储格式化失败,可能是cluster ID冲突" return 1 fi } # 函数:启动Kafka服务器 start_kafka() { echo echo "=== 第3步:启动Kafka服务器 ===" echo "配置文件: $CONFIG_FILE" echo "正在启动Kafka..." echo "提示: 使用 Ctrl+C 停止服务器" echo bin/kafka-server-start.sh "$CONFIG_FILE" } # 主逻辑 main() { # 尝试格式化存储 if ! format_storage; then echo echo "⚠️ 检测到cluster ID冲突,正在清理并重试..." cleanup_logs echo echo "=== 重新尝试格式化 ===" if ! format_storage; then echo "✗ 重试后仍然失败,请检查配置" exit 1 fi fi # 启动Kafka start_kafka } # 捕获中断信号 trap 'echo -e "\n\n🛑 接收到停止信号,正在关闭Kafka..."; exit 0' INT TERM # 检查必要文件是否存在 if [ ! -f "$CONFIG_FILE" ]; then echo "✗ 配置文件不存在: $CONFIG_FILE" exit 1 fi if [ ! -f "bin/kafka-storage.sh" ]; then echo "✗ kafka-storage.sh 不存在,请确认在正确的Kafka目录中运行" exit 1 fi # 执行主逻辑 main 复制代码
给它加上权限:chmod +x start-kafka.sh 复制代码
运行它:./start-kafka.sh 复制代码
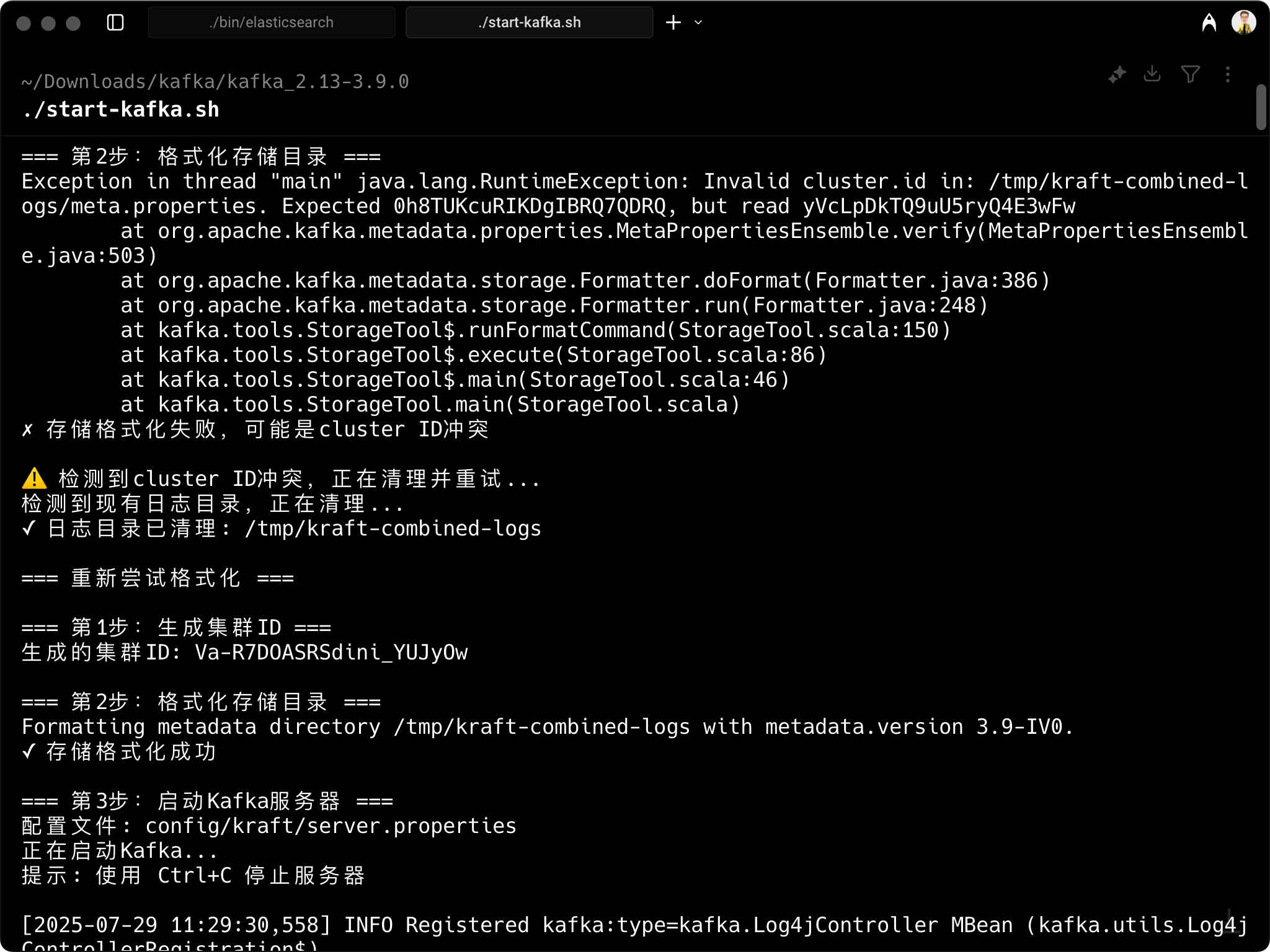
验证安装
# 创建主题 bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092 # 查看主题列表 bin/kafka-topics.sh --list --bootstrap-server localhost:9092 # 查看主题详情 bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092 复制代码
应该能看到刚创建的测试主题。
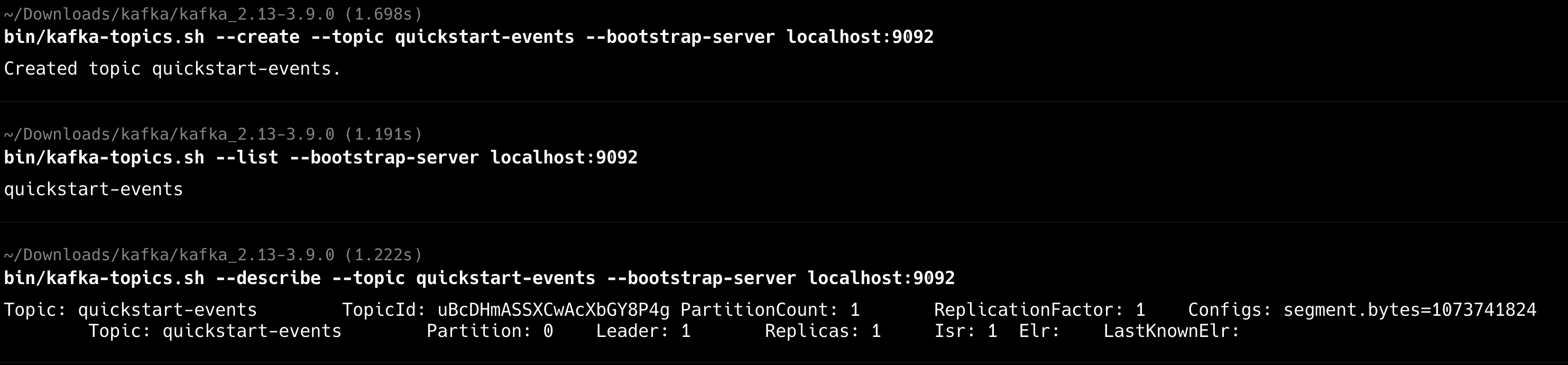
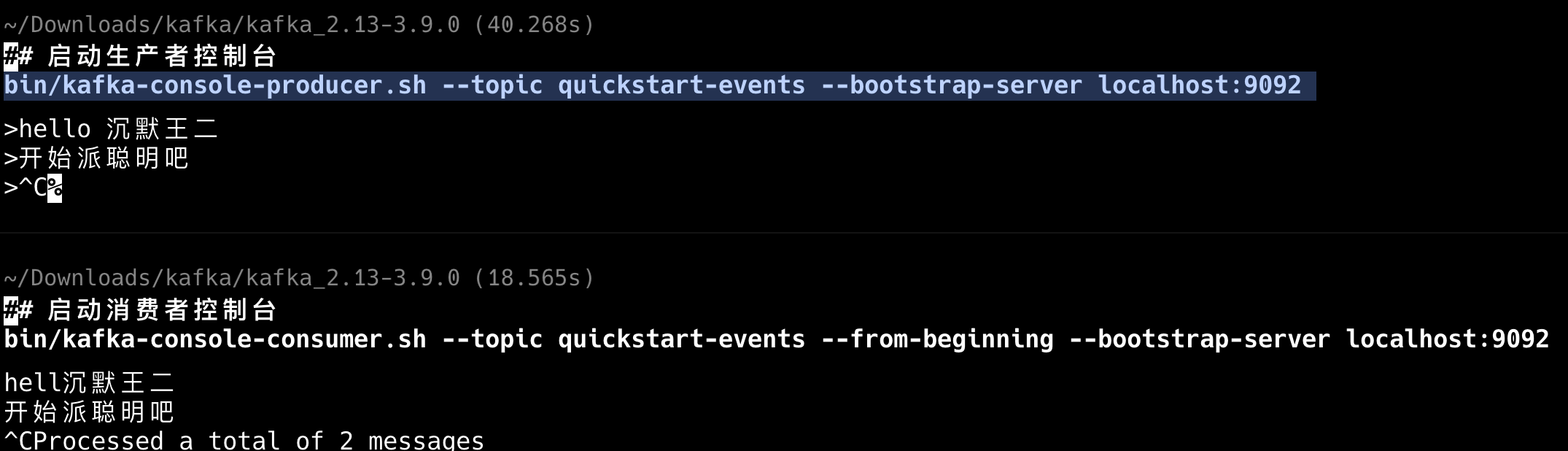
发送测试消息:# 启动生产者控制台 bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092 复制代码
接收消息:# 启动消费者控制台 bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092 复制代码
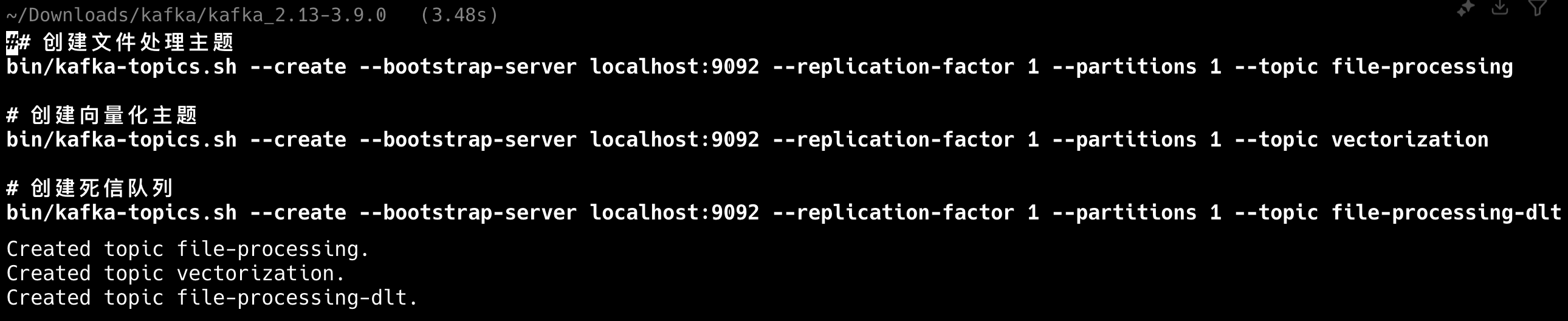
创建派聪明所需主题
# 创建文件处理主题 bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic file-processing # 创建向量化主题 bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic vectorization # 创建死信队列 bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic file-processing-dlt 复制代码
七、初始化项目
第一步,申请派聪明源码权限
申请方式查看这个帖子:https://paicoding.com/column/10/3
第二步,用 IntelliJ IDEA 导入项目
第三步,在 application-dev.yml 中更改 MySQL 的配置连接和用户名密码。
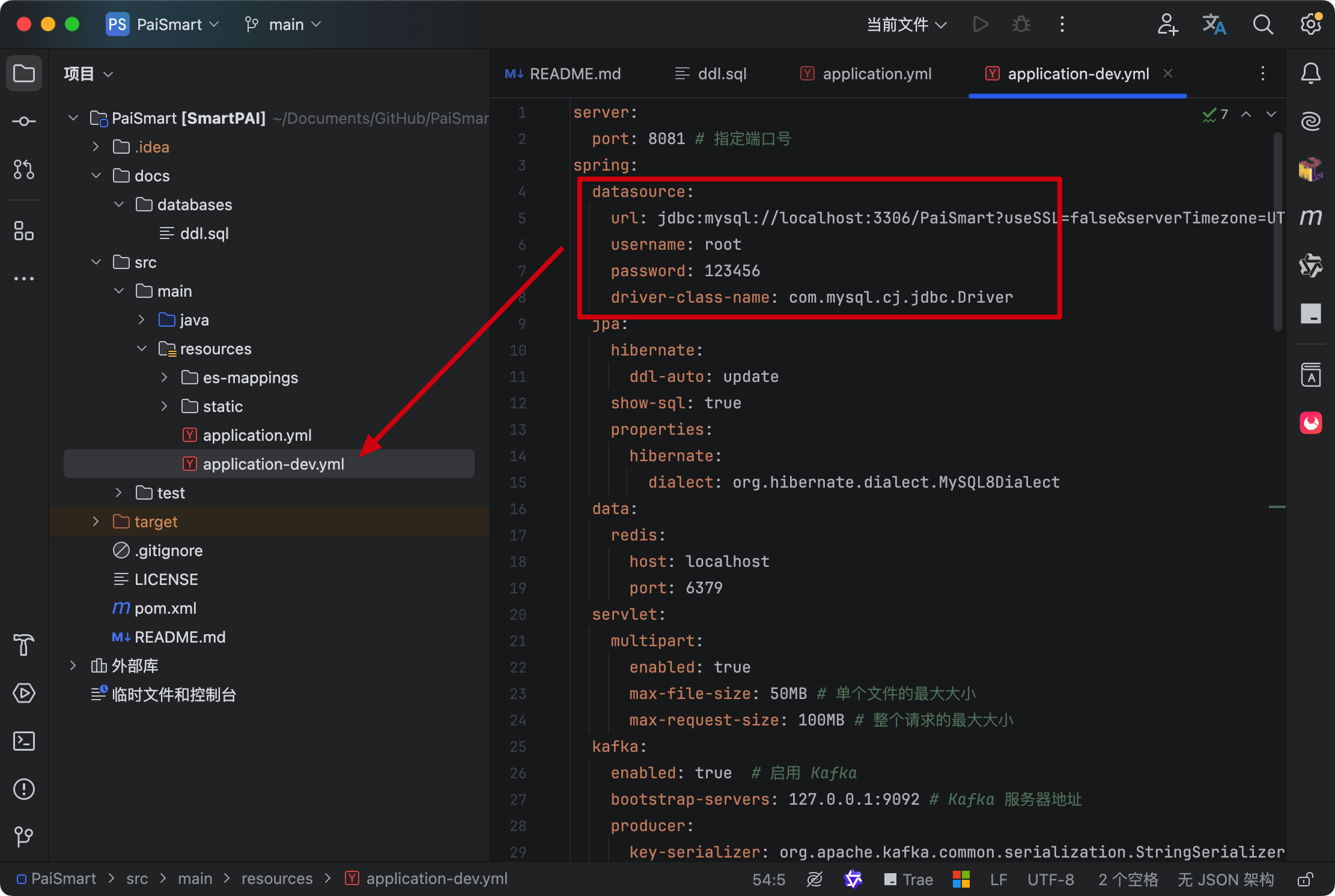
第四步,配置 Elasticsearch 索引
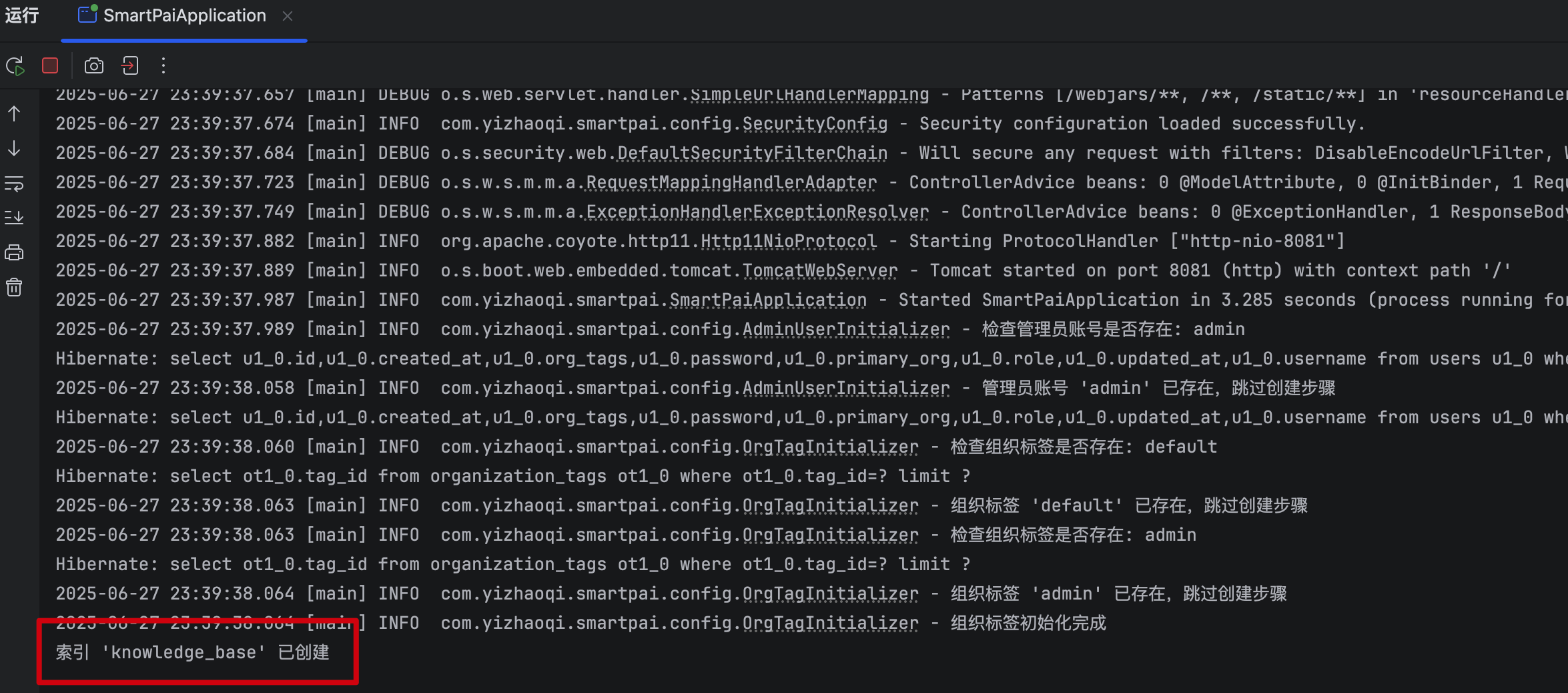
参考【✅Elasticsearch 8.10 安装】启动 ES 后,启动项目后,会在控制台看到这样一条信息:
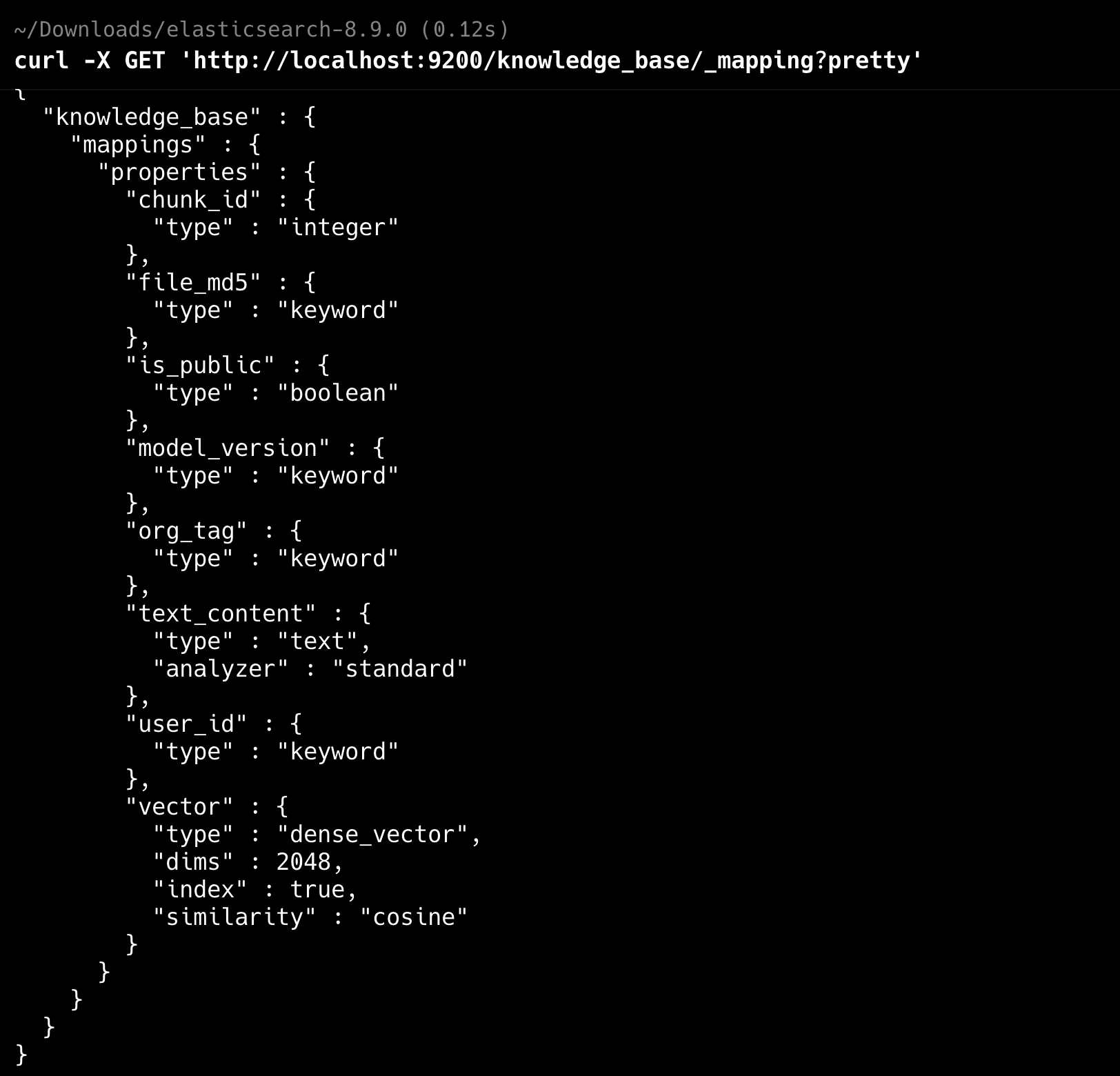
可以通过 curl -X GET 'http://localhost:9200/knowledge_base/_mapping?pretty'来查看索引(http 模式下),如果是 HTTPS 模式,请查看:HTTPS 模式下 ES 索引的获取和删除
确认 application-dev.yml 中的配置是正确的。
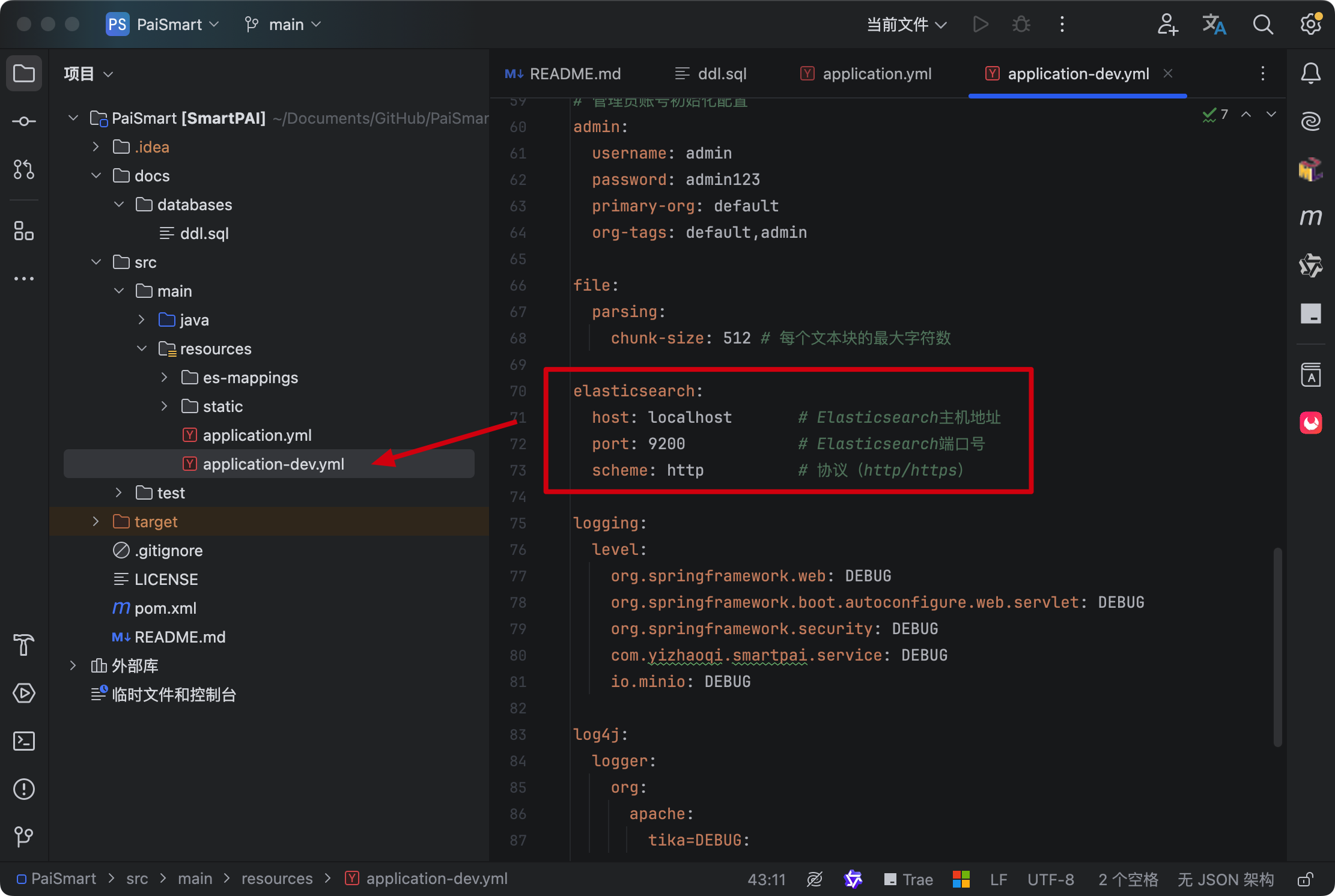
第五步,确认自己的 Redis 是启动的
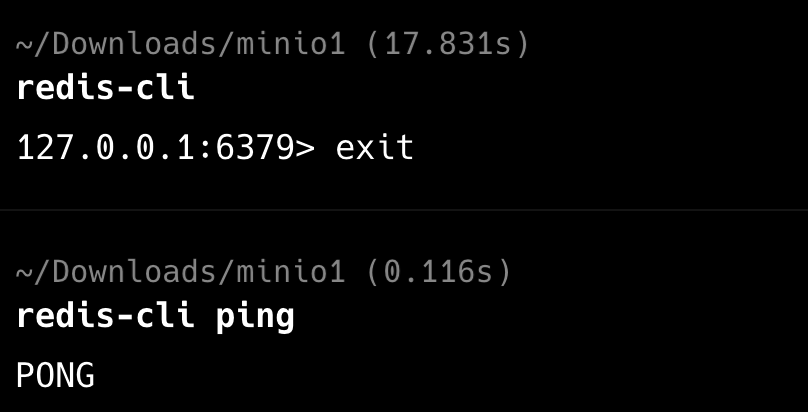
application-dev.yml 中的配置也是正确的。
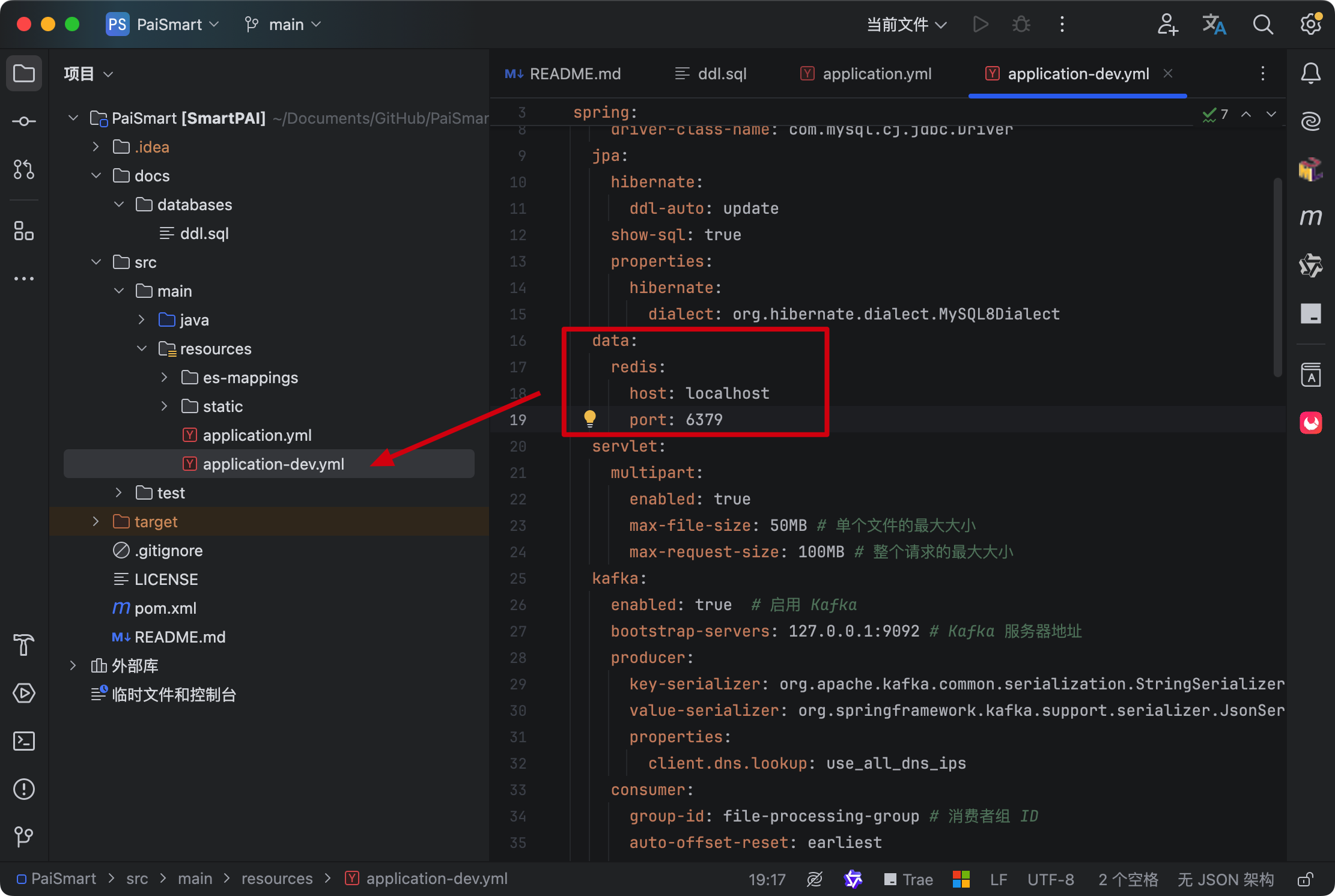
第六步,确认自己的 MinIO 是启动的
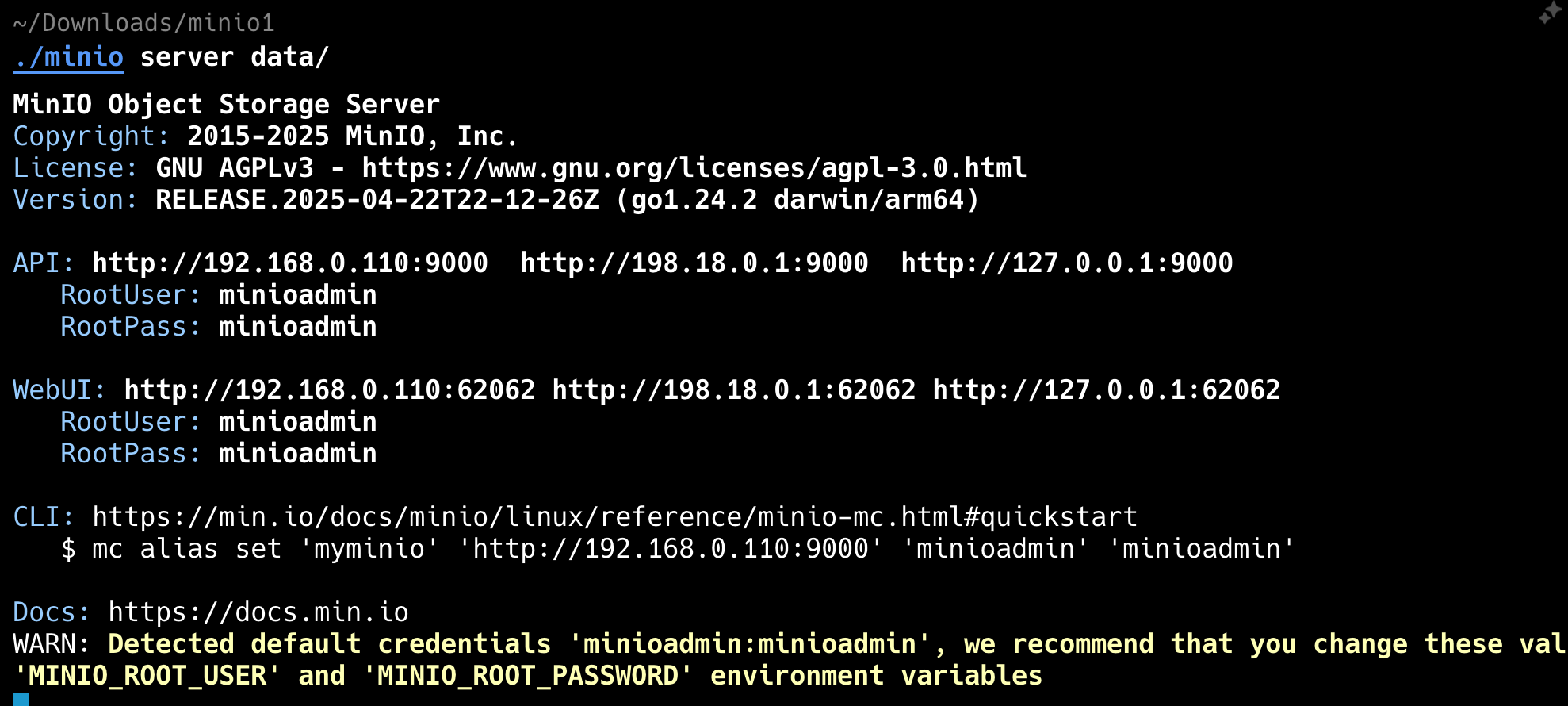
并且 application-dev.yml 中的配置是匹配的
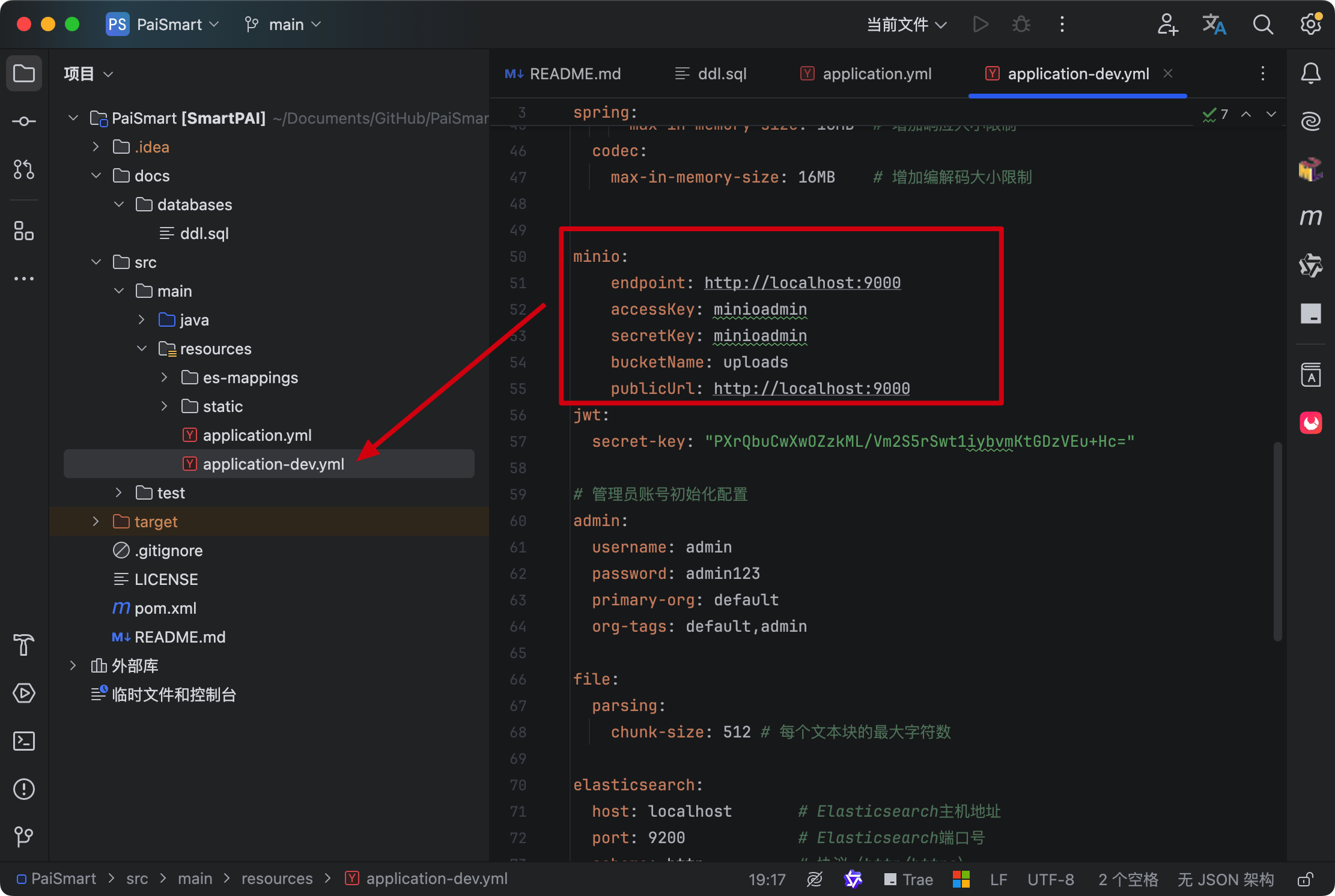
第七步,确认 Kafka 是启动的
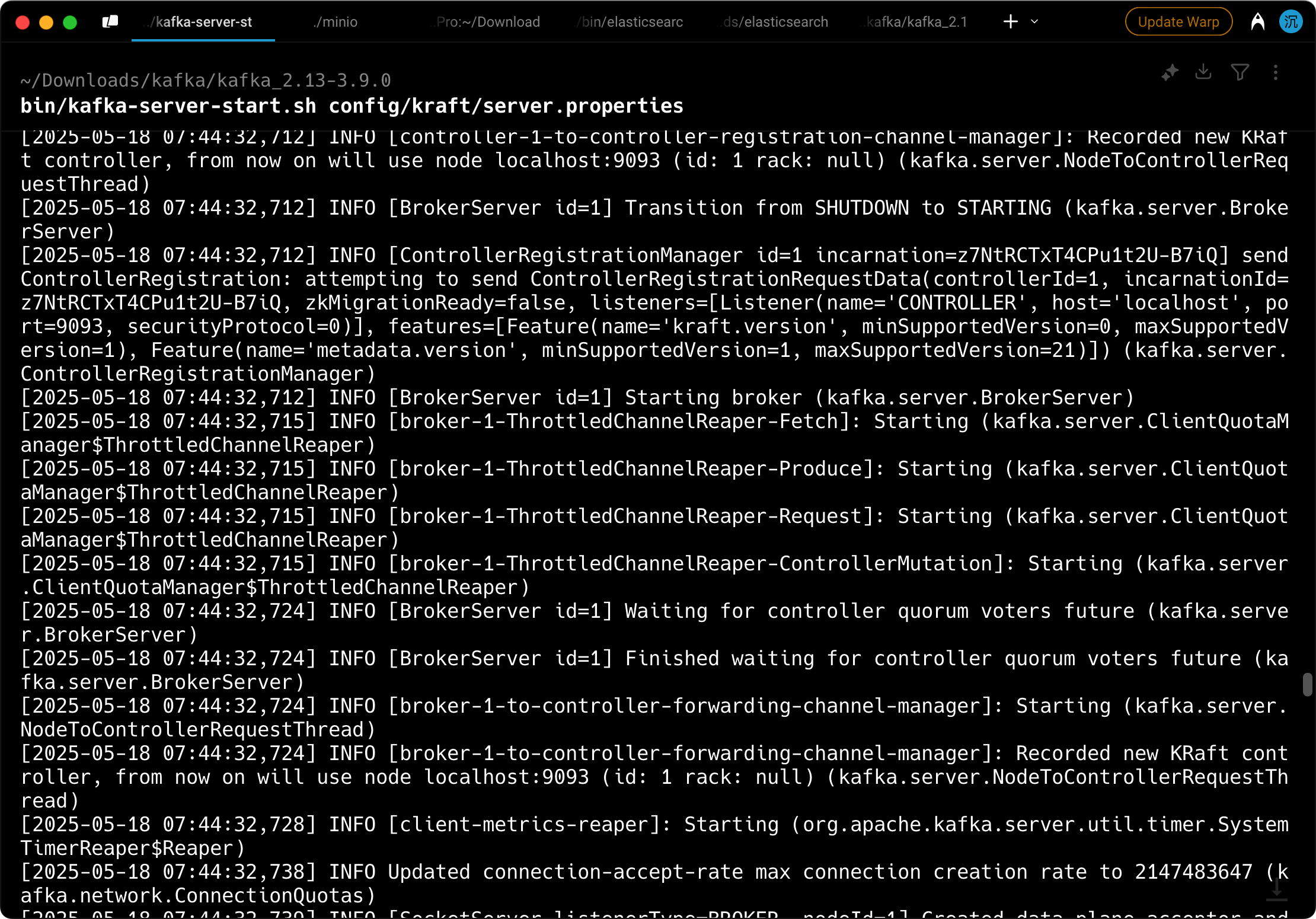
并且 application-dev.yml 中的配置也是匹配的
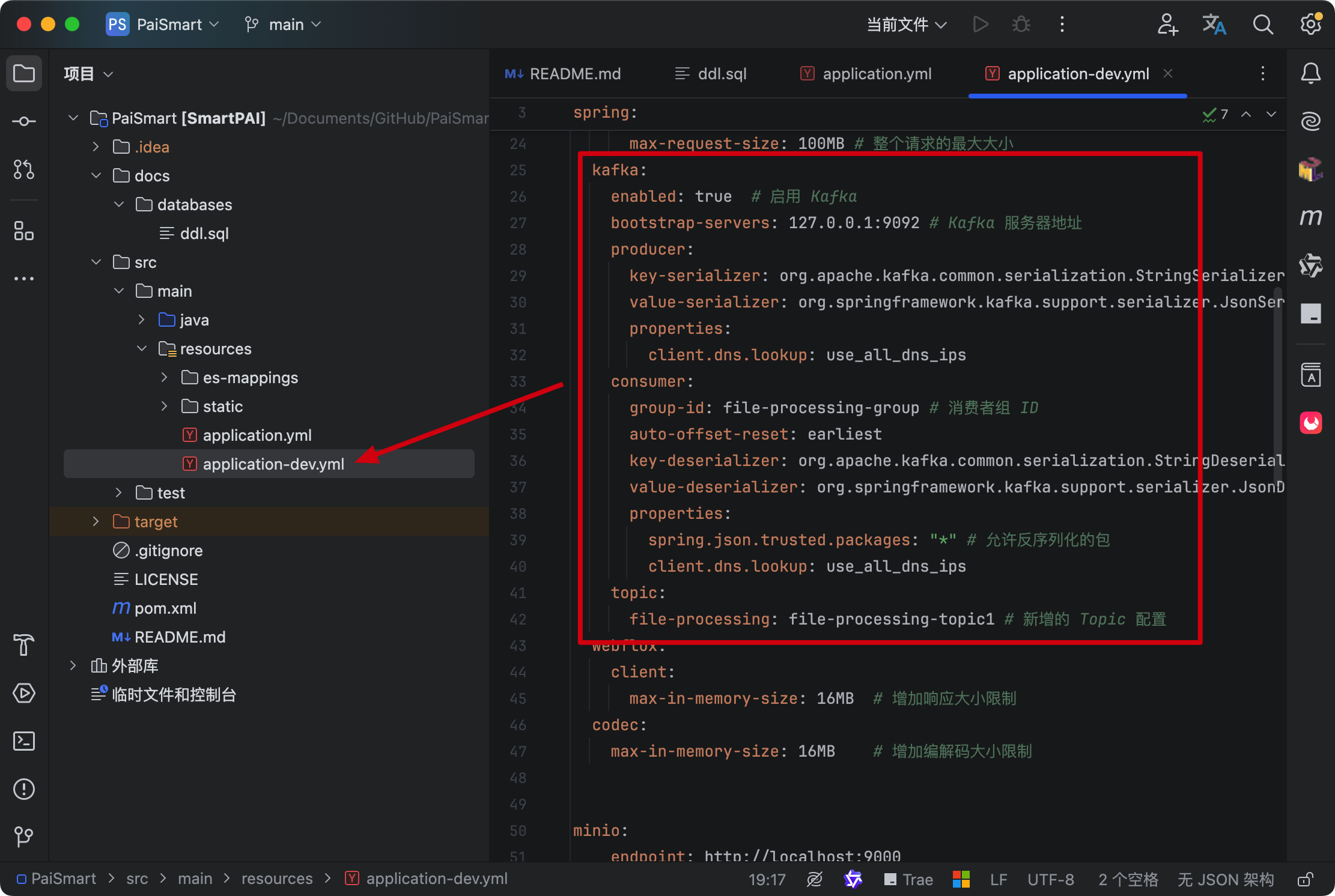
第八步,确认 DeepSeek API 填写正确

官方 api 参考:✅DeepSeek API 申请
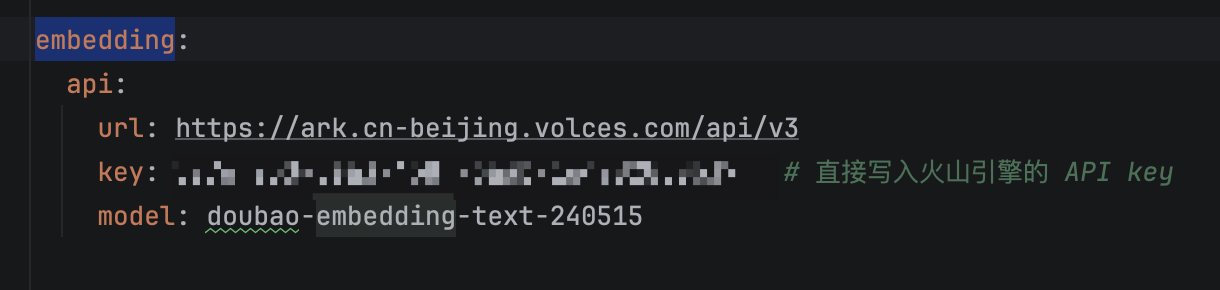
第九步,确认向量 API 填写正确
向量化 API 申请,目前已经改用阿里的 embedding 模型,支持 2048 维,可以和 ES 8.10 兼容,豆包竟然下架了 2048 维模型,垃圾,不向下兼容。
八、功能测试
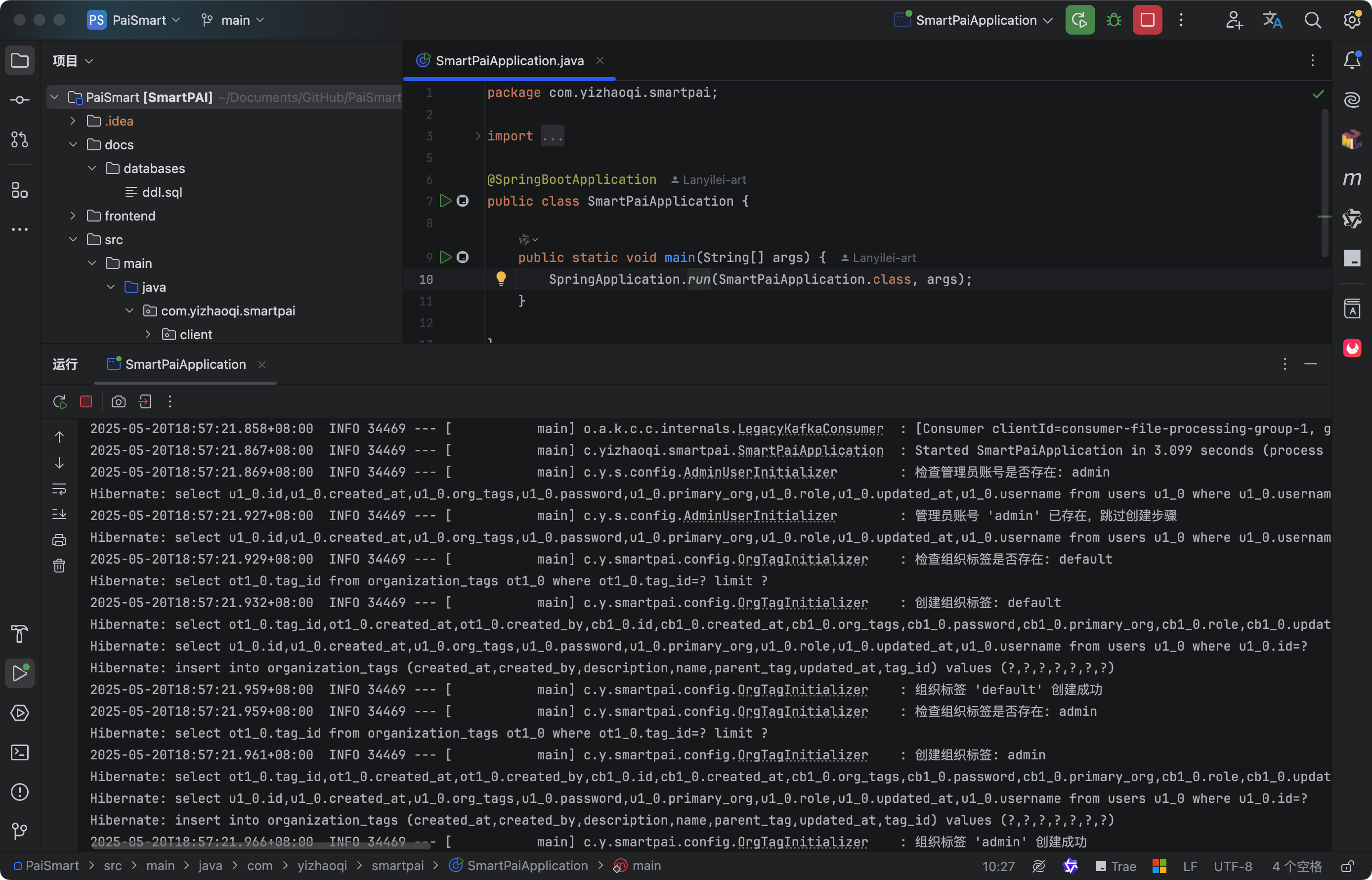
1.运行后端项目
使用 IDEA 打开项目后启动 main 类 SmartPaiApplication,如果控制台没有报错,就说明后台服务启动成功了。
如果有任何错误,可以在评论区贴出你的问题,或者在星球里提出问题,或者在 VIP 群里发错误截图和日志,我会第一时间跟进。
如果 8081 端口被占用,起不来,请直接 kill 掉相关进程。
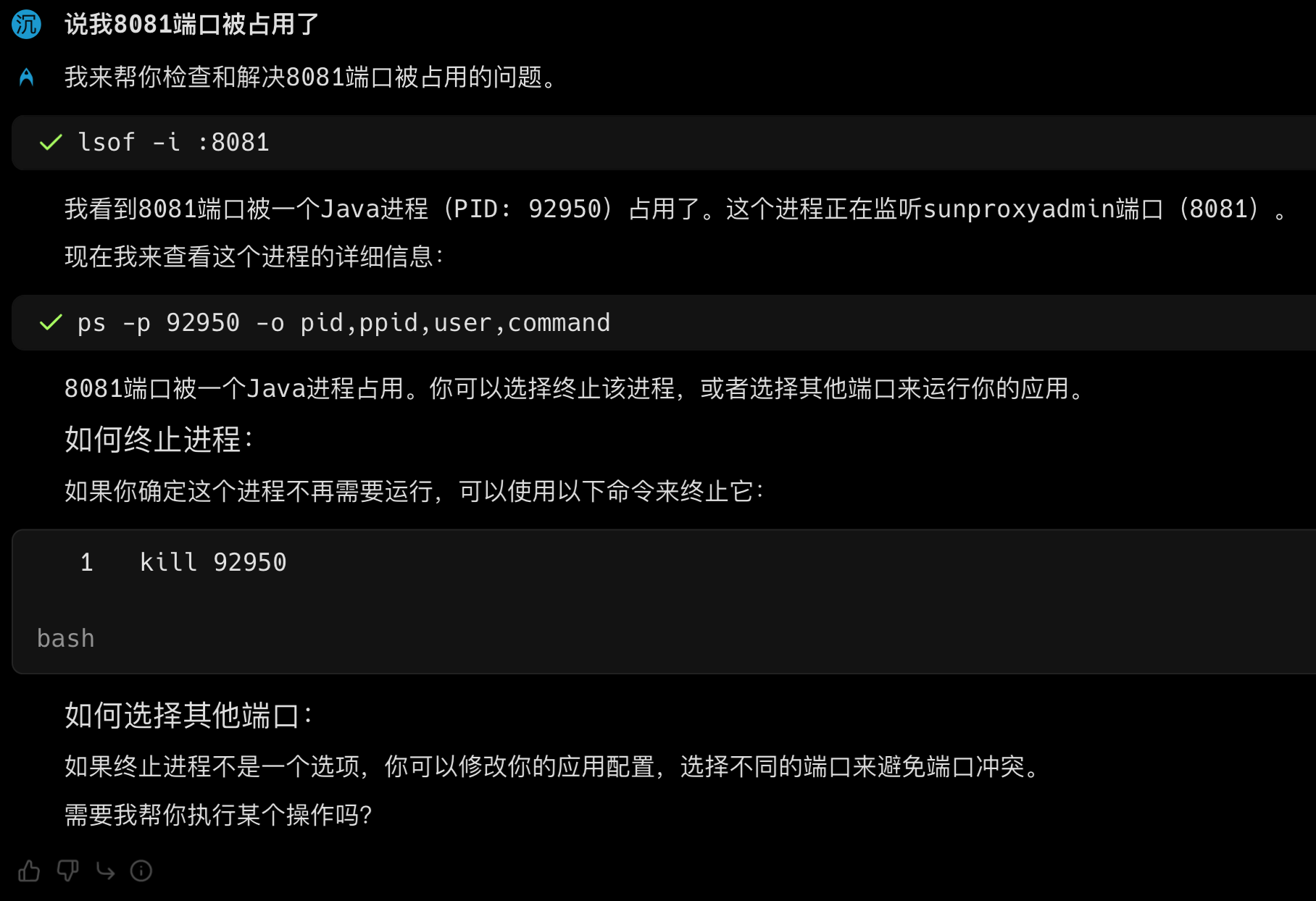
Lan 在开发模式下运行的方式:# 如果要在开发环境中运行 ./mvnw spring-boot:run 复制代码
2.访问前端测试页面
如果你暂时还没有拉取 web 端,那么可以直接通过测试页面确认服务是否启动成功:http://localhost:8081/test.html
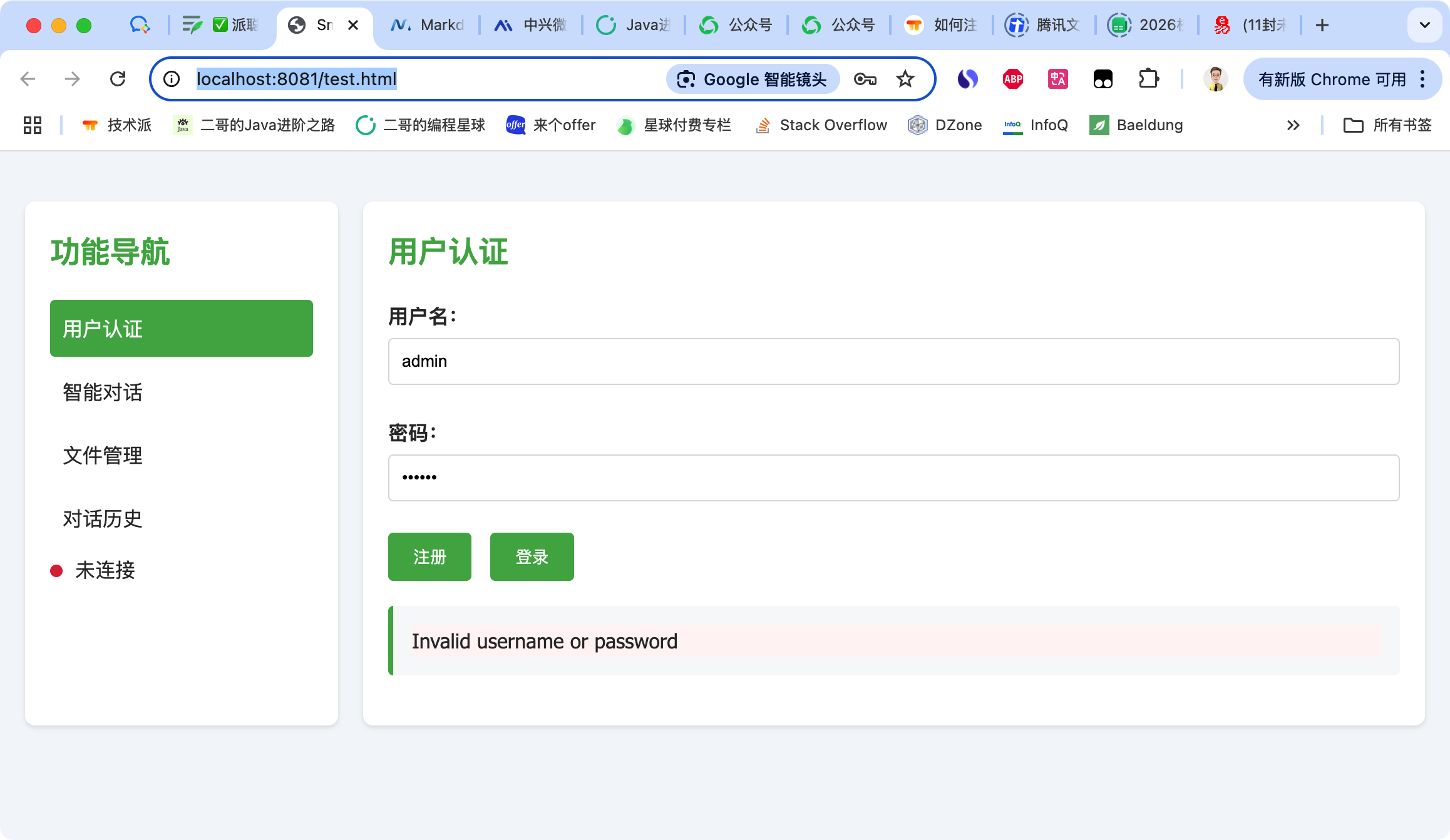
至于 admin 的默认密码,这里留个防盗传送门,球友们可以添加我的微信 itwangersb 来获取,或者扫下面的二维码,两个微信号都是可以的。
3.运行 Web 前端
可以用 VSCode 或者 Cursor 导入前端项目,在 frontend 目录下。
然后在终端执行 pnpm i 命令安装依赖,注意切到 frontend 目录下(首先要有 Node.js 环境,这个大家在网上找点教程或者问一下 AI,我这里因为已经安装好了环境,所以没办法给大家演示):
然后执行 pnpm run dev 命令启动前端:
然后直接点击控制台的链接就可以访问前端了: