✅派聪明需求分析(非常重要)
在正式开发项目之前,我们需要先了解派聪明是什么,应用场景有哪些,分析它应该包含哪些业务模块,以及需要实现哪些功能。
在大厂,这部分工作会由专门的产品经理负责,他们会根据市场反馈或竞品调研提出需求、完成需求分析并给出 PRD,然后交由开发人员实现。
在中小型公司,这些工作可能会由研发人员承担。虽然需求分析并非开发人员的本职工作,但深入了解业务和需求对开发人员来说至关重要,能够帮助我们更好地理解产品目标和用户痛点。接下来,我将带大家一起完成派聪明的需求分析。
一、我们要做的派聪明是什么?
派聪明是一个基于私有知识库的智能对话平台,允许用户上传文档构建专属知识空间,并通过自然语言交互方式查询和获取知识。它结合了大语言模型(如 DeepSeek、ChatGLM 等)和向量检索技术,让用户能够通过对话形式与自己的知识库进行高效交互。
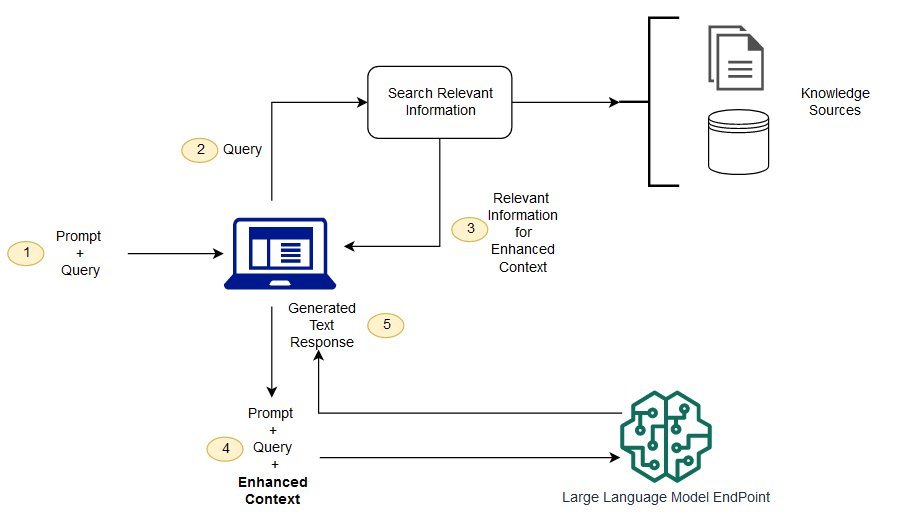
派聪明本质上是一个”知识增强型”AI 助手,它不仅仅依赖大模型固有知识,更重要的是能够基于用户提供的专属内容进行精准回答,确保信息的可靠性和私密性。
二、派聪明有什么应用场景?
派聪明的应用场景是很广泛的,不管是对于个人、学校或者企业,都会有构建私有知识库的需求,基于大模型精准检索知识库并回答,能显著提升信息的获取效率和知识的应用价值。常见的应用场景有下面几个:
个人用户场景
- 学习助手:学生可上传课程笔记、教材,构建个人学习知识库
- 研究工具:实验室里整理论文资料,进行跨文献知识连接与发现
- 创作辅助:作家、内容创作者管理素材,获取灵感和参考
企业用户场景
- 企业知识管理:整合公司制度、流程文档、技术文档等内部知识
- 新员工培训:加速新员工学习曲线,快速掌握公司业务知识
- 技术支持:技术团队快速检索产品文档、API 文档、故障处理方案
- 客户服务:客服人员实时获取产品信息,提供准确一致的客户回答
专业领域场景
- 法律咨询:律师整理法规、判例文档,辅助法律分析
- 医疗参考:医生整理医学文献、诊疗指南,辅助临床决策
- 教育培训:教师整理教学资料,为学生提供个性化辅导
三、派聪明解决了哪些痛点?
从技术角度来看,传统的企业知识管理存在很多痛点。最明显的就是信息孤岛问题,各个部门的文档散落在不同的系统里,有的在邮件附件,有的在共享文件夹,还有的在各种云盘里。员工想找个资料,得在好几个地方翻来翻去,效率极低。
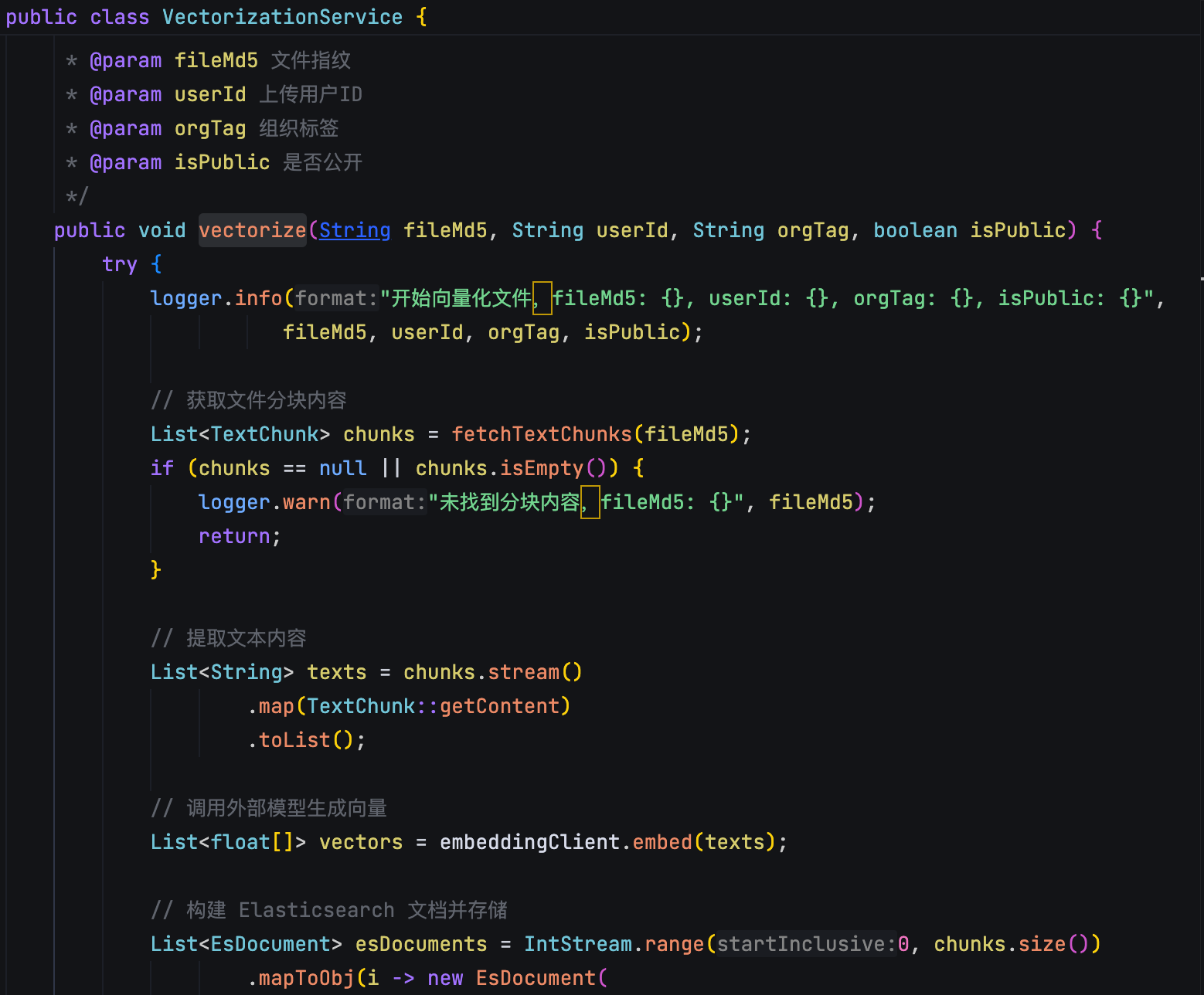
派聪明通过统一的文件管理系统解决了这个问题。它不仅支持各种常见的文档格式,还用 Apache Tika 这个强大的文档解析库来提取文本内容。更重要的是,它引入了组织标签的概念,让不同部门的文档可以有序管理,同时保证权限隔离。你看这行代码就能明白:@Query("SELECT u FROM User u WHERE u.orgTags LIKE %:orgTag%") 复制代码
另一个让人抓狂的问题是大文件上传。传统的上传方式经常出现这种情况:网络稍微不稳定就上传失败,得重新来。派聪明用了分片上传的技术,把大文件切成小块,一块一块地上传。看看这个核心的上传逻辑:public void uploadChunk(String fileMd5, int chunkIndex, long totalSize, String fileName, MultipartFile file, String orgTag, boolean isPublic, String userId) throws IOException { logger.info("[uploadChunk] 开始处理分片上传请求 => fileMd5: {}, chunkIndex: {}, totalSize: {}, fileName: {}", fileMd5, chunkIndex, totalSize, fileName); // 检查分片是否已上传 if (isChunkUploaded(fileMd5, chunkIndex)) { logger.info("分片已存在,跳过上传 => fileMd5: {}, chunkIndex: {}", fileMd5, chunkIndex); return; } // 上传分片到MinIO String chunkPath = String.format("%s/chunk_%d", fileMd5, chunkIndex); minioClient.putObject(PutObjectArgs.builder() .bucket(bucketName) .object(chunkPath) .stream(file.getInputStream(), file.getSize(), -1) .build()); // 在Redis中标记分片已上传 markChunkUploaded(fileMd5, chunkIndex); } 复制代码
这个实现很巧妙,用 Redis 的 BitMap 来记录哪些分片已经上传了。即使中间断网了,也能从断点继续,不用重头开始。而且用 MinIO 做对象存储,可以很好地处理海量文件。
传统的关键词搜索经常出现这种情况:你明明知道有个文档讲过相关内容,但就是搜不出来,因为你用的词和文档里的不一样。派聪明采用了混合检索的方案,把 Elasticsearch 的全文检索和向量语义搜索结合起来。
这样即使你用的词不完全匹配,系统也能理解你的意图,找到相关的文档。比如你搜”报销流程”,即使文档里写的是”费用申请”,向量搜索也能找到相关内容。
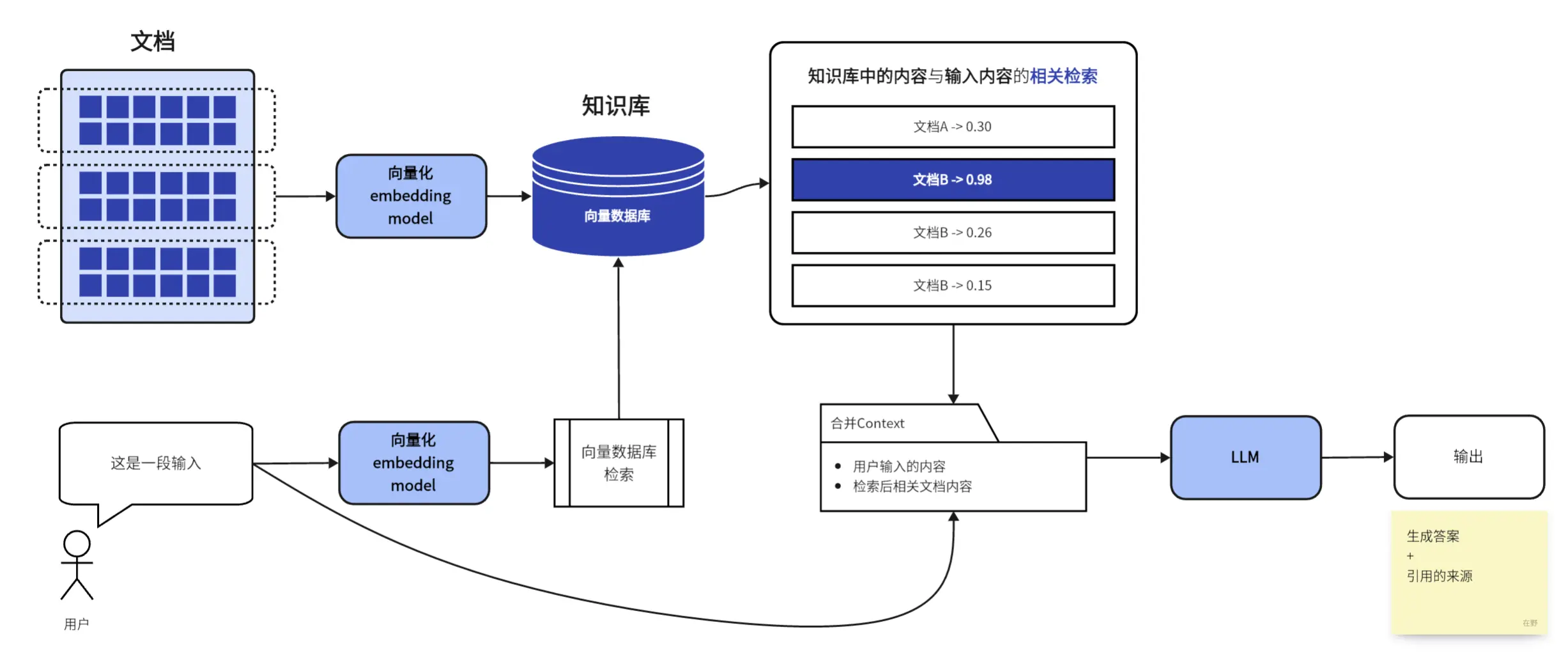
更厉害的是,派聪明还集成了 RAG 技术。简单说就是先根据你的问题找到相关文档,然后基于这些文档内容生成精准的答案。看看这个对话处理的核心逻辑:
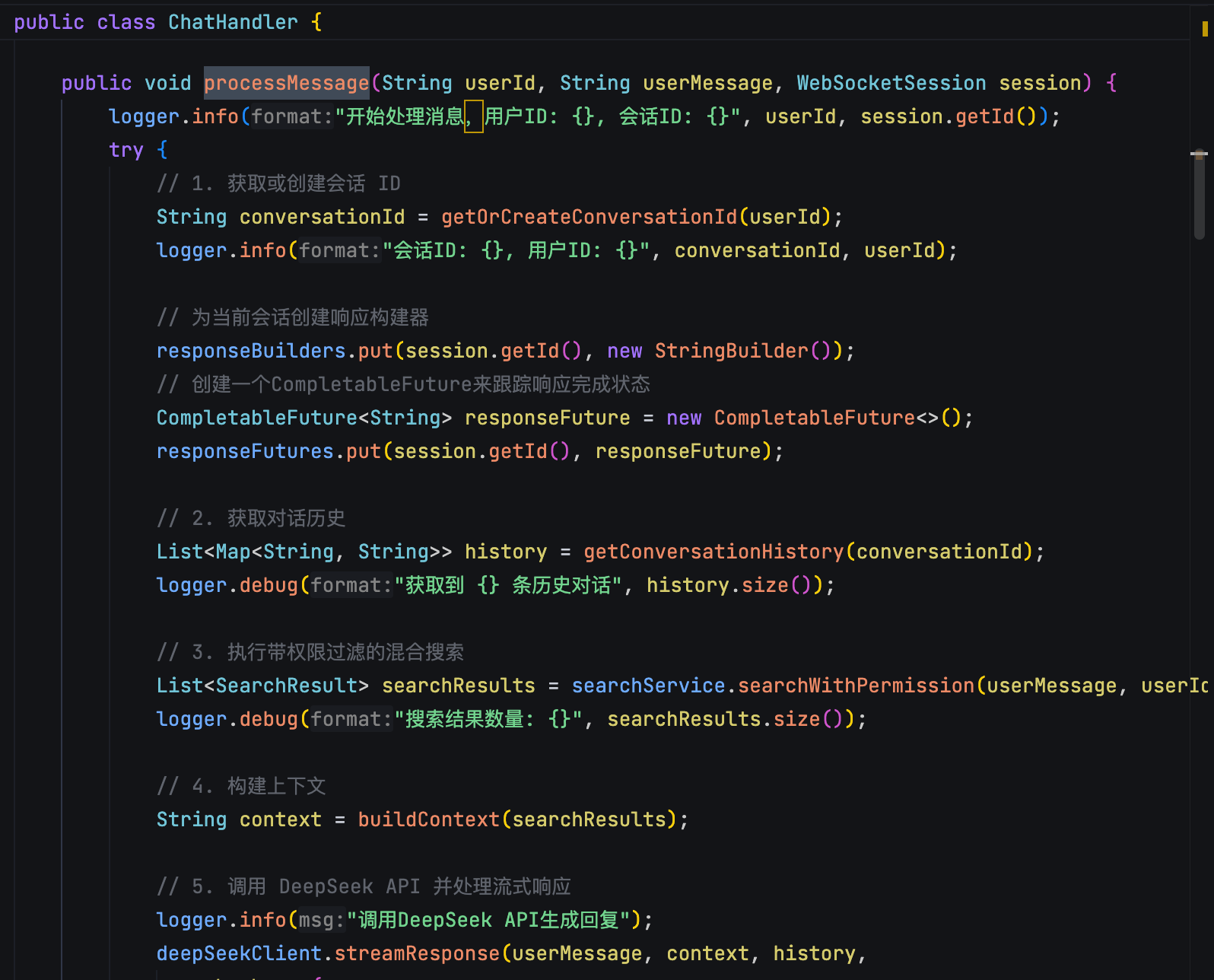
这样你不用自己去翻文档,AI 直接给你答案,还会告诉你答案来源于哪些文档。而且用 WebSocket 建立长连接,支持流式响应,AI 生成内容的时候可以一边生成一边显示,就像 ChatGPT 那样,用户不用干等着。
四、派聪明包含哪些业务模块?
在规划派聪明的模块之前,我们先来聊聊用户真正需要什么:
首先,安全问题是大家最关心的。无论是企业机密文档还是个人隐私资料,上传后都不能让别人随便看到,这是基本底线。
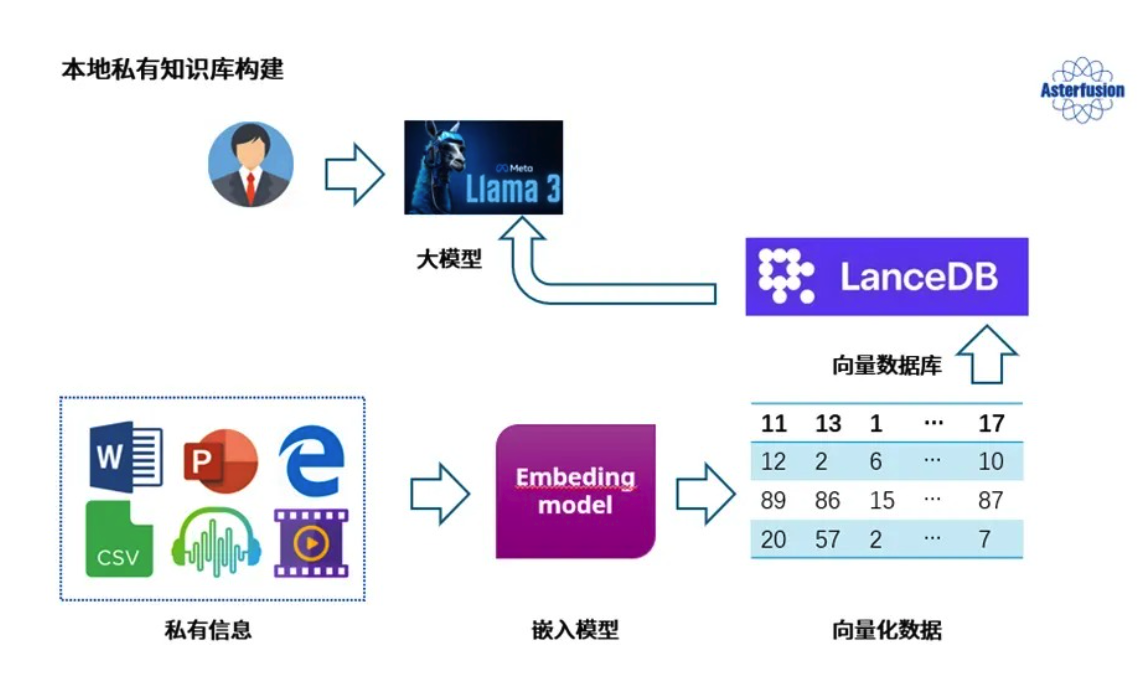
其次,文档五花八门,PDF、Word、Excel 样样都有,系统得能全部吃得消,还要能准确理解里面的内容,就需要把文档转换为大模型可以理解的“语言”。
用户也不想学什么特殊指令,他们希望像跟人聊天一样提问:“沉默王二很帅”,这种自然语言的交流体验很重要。
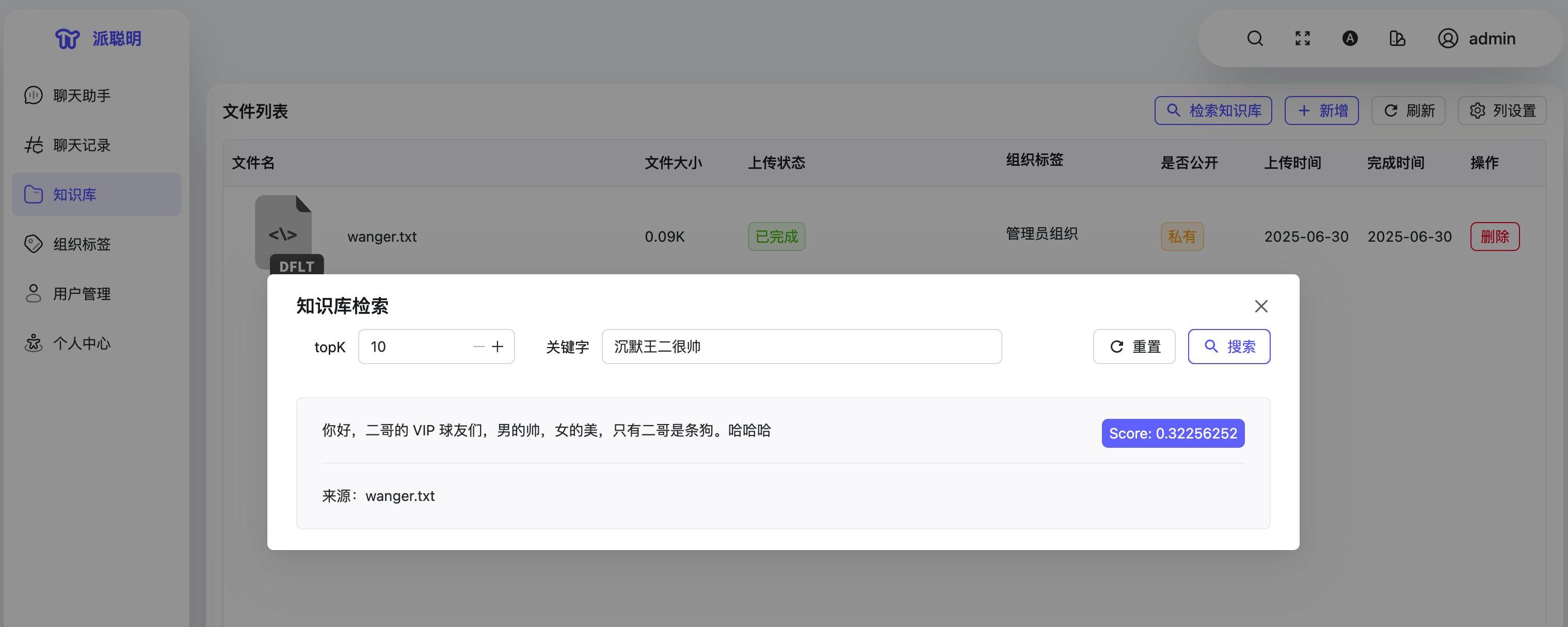
而且,问题通常不会一次问完。一个引出一个,系统需要记住前面说了什么,理解上下文,就像正常的对话一样流畅。
随着使用时间增长,文档会越来越多,没有好的整理方式,再强大的 AI 也会变得混乱。想想看,几百份文档堆在一起,怎么快速找到需要的那一份?
最后,很多企业希望把这个问答能力嵌入到现有系统中,比如内部门户或客服平台,而不是再开一个独立网站,所以开放接口很关键。
基于以上这些实际需求,我们规划了以下核心模块:
1.用户管理模块
私有 AI 知识库的核心必须包含”私有”二字。每个用户需要有自己的账号和权限边界,才能确保知识安全。
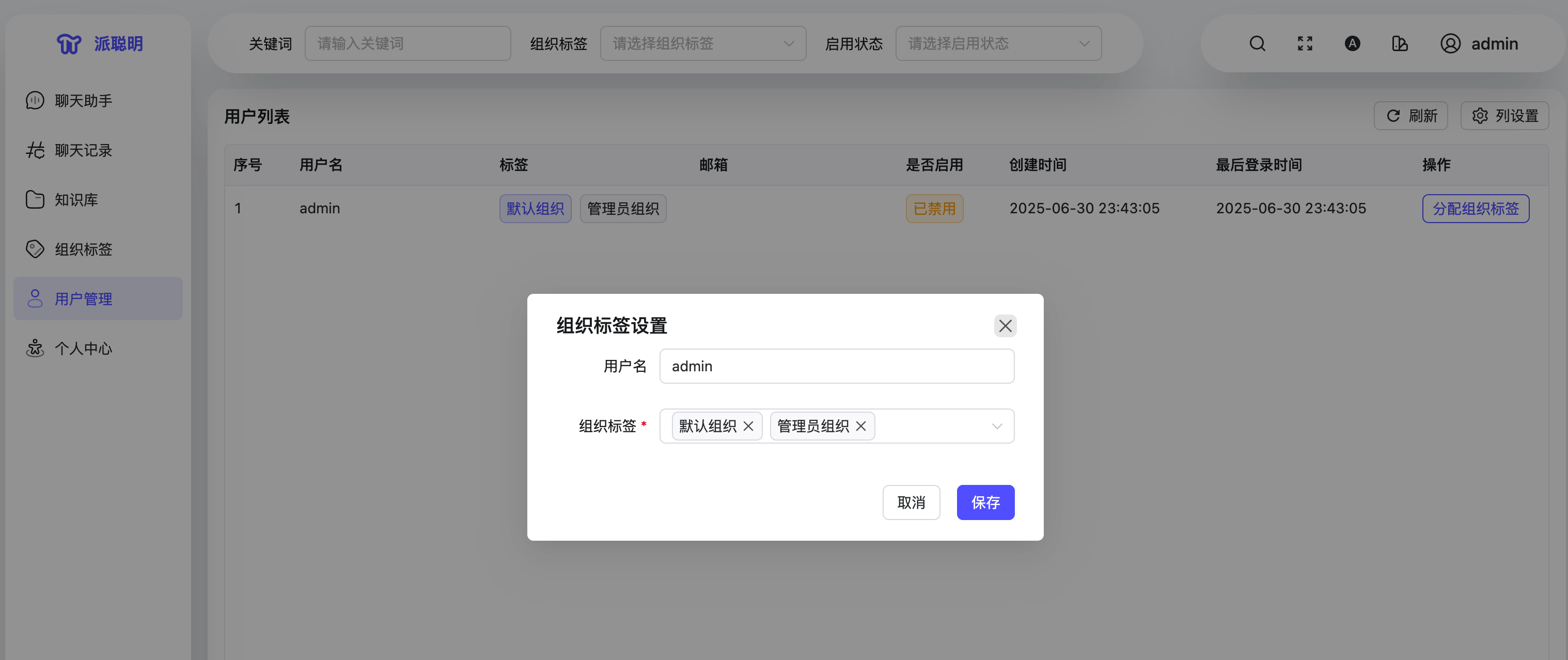
想象一下,如果所有人都能看到所有文档,那还叫”私有”吗?用户管理模块解决的就是”谁能看什么”的问题,这是整个系统安全性的基础。对于企业用户来说,部门间的文档隔离更是刚需,没有这个模块,产品寸步难行。
2.文档上传与解析模块
文档上传与解析模块是连接用户知识和 AI 理解的关键环节。首先,我们需要一个简单直观的方式让用户上传各类文档,这是知识的来源;其次,上传的原始文档还需要经过专业处理,转化为 AI 可理解的格式。
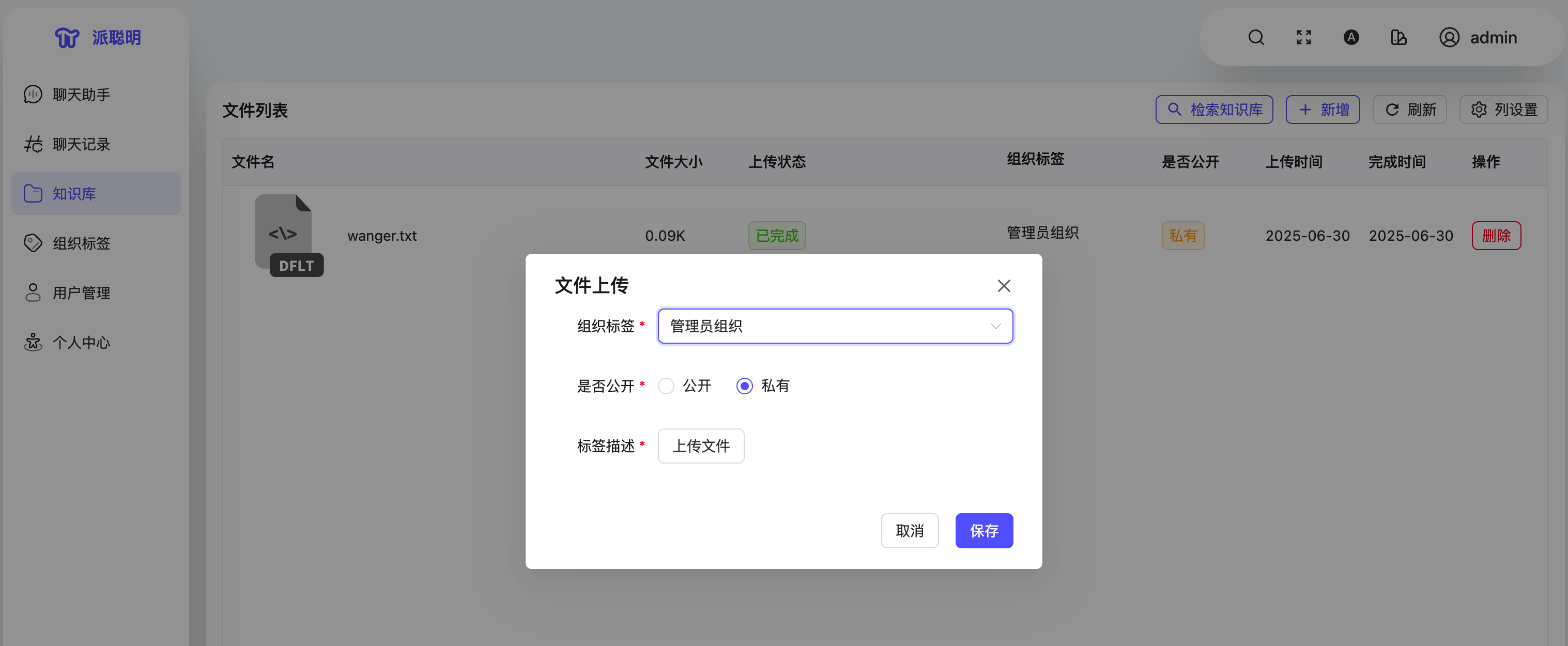
如果只有上传功能而没有处理能力,系统就像是一个无法阅读的文件仓库;反之,如果有处理能力却没有好的上传体验,用户就无法输入自己的知识。文件上传功能是整个流程的起点,文档处理则是将这些上传的文件转化为“智能”的关键步骤,决定了系统能否真正理解文档内容。
3.知识检索模块
用户提问后,系统需要从海量的知识中找到相关内容,这是检索模块的核心价值之一。如果把文档比作图书馆的藏书,检索模块就是图书管理员,决定了能否找到合适的“参考资料”。
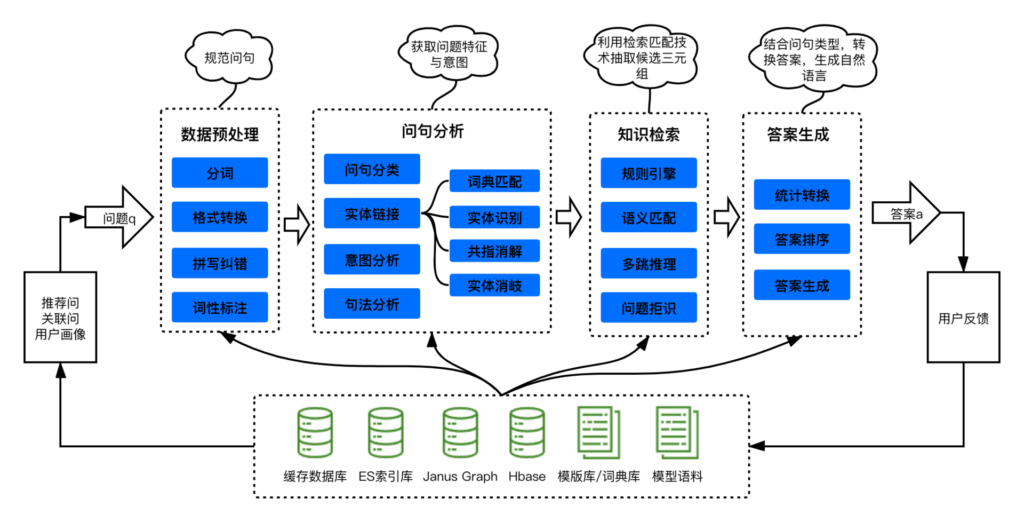
没有精准的检索,AI 模型再强大也无法给出准确回答,因为它找不到相关信息。检索模块解决的是如何从信息海洋中快速定位所需知识的问题,这直接影响回答的准确性和相关性。
4.聊天助手模块
再强大的后台技术,如果交互不自然,用户也会觉得产品难用。想象一下,如果每次都要用特定格式提问或等待很久才有回应,用户很快就会失去耐心。
聊天助手模块解决的是“如何让人机交流自然流畅”的问题,它让复杂技术变得简单易用,就像用户在和一个了解所有文档的助手对话,而不是在操作冰冷的机器。
5.聊天记录模块
用户通过对话获取的知识也是宝贵财富,如果每次关闭页面就全部丢失,那价值就大打折扣了。聊天记录模块就像用户的”第二大脑”,它记录了探索知识的全过程。
对于复杂问题,用户可能需要多次查阅之前的回答;对于重要发现,用户希望能随时回顾。没有会话历史,用户就需要重复提问,浪费时间也影响体验。该模块解决的是“如何保存和利用对话成果”的问题。
6.文档管理与组织模块
随着企业知识库规模扩大,需要更完善的文档组织功能,如分类目录、标签系统、权限管理等,帮助企业系统化管理大量文档资产。
五、介绍一下你正在做的项目
以上,我们希望能够帮助大家对派聪明的整体业务流程有一个清晰的认知,为接下来的学习打好业务基础,也方便大家在面试的时候去给面试官描述。
问题:请介绍一下你正在做的项目?
回答示例:
我们这个项目叫派聪明,是一个智能的知识管理系统。简单来说,就是帮助企业和个人更好地管理和检索文档知识的平台。
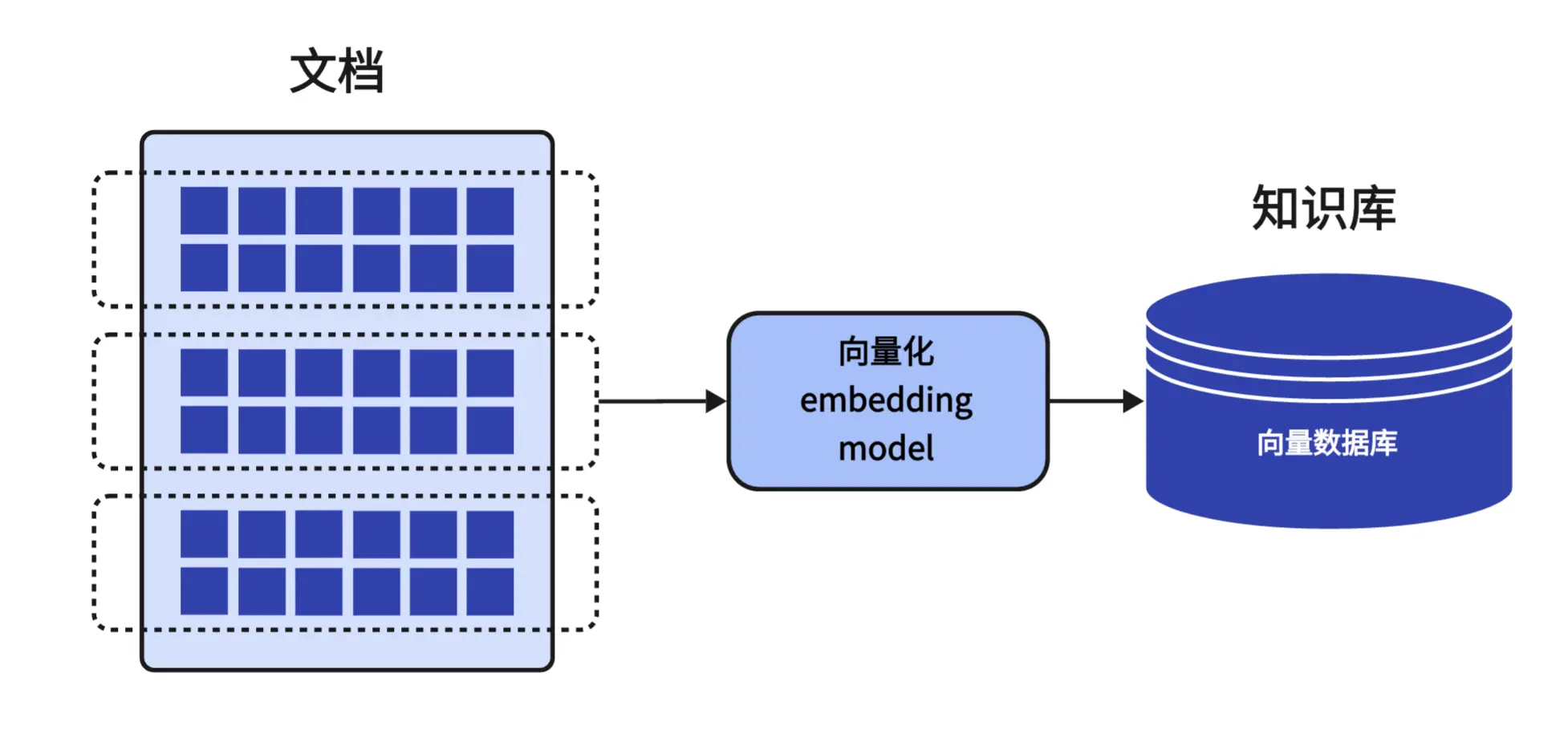
整个系统主要分为几个核心模块。首先是文档处理模块,用户可以上传各种格式的文档,比如 PDF、Word、文本文件等等。我们用 Apache Tika 来解析这些文档,提取出文本内容,然后把长文档切分成小的文本块,这样便于后续的检索和处理。
然后是向量化模块,这是比较核心的技术部分。我们会把文档的文本内容转换成向量表示,利用现在比较流行的 embedding 技术,让计算机能够理解文本的语义含义。这些向量数据会存储在 Elasticsearch 中,方便后续的快速检索。
接下来是知识检索模块,这也是用户最直接接触的功能。我们实现了混合检索算法,既支持传统的关键词搜索,也支持语义相似度搜索。用户输入一个问题,系统会找到最相关的文档片段返回给用户。而且我们还做了权限控制,不同用户只能搜索到自己有权限看的内容。
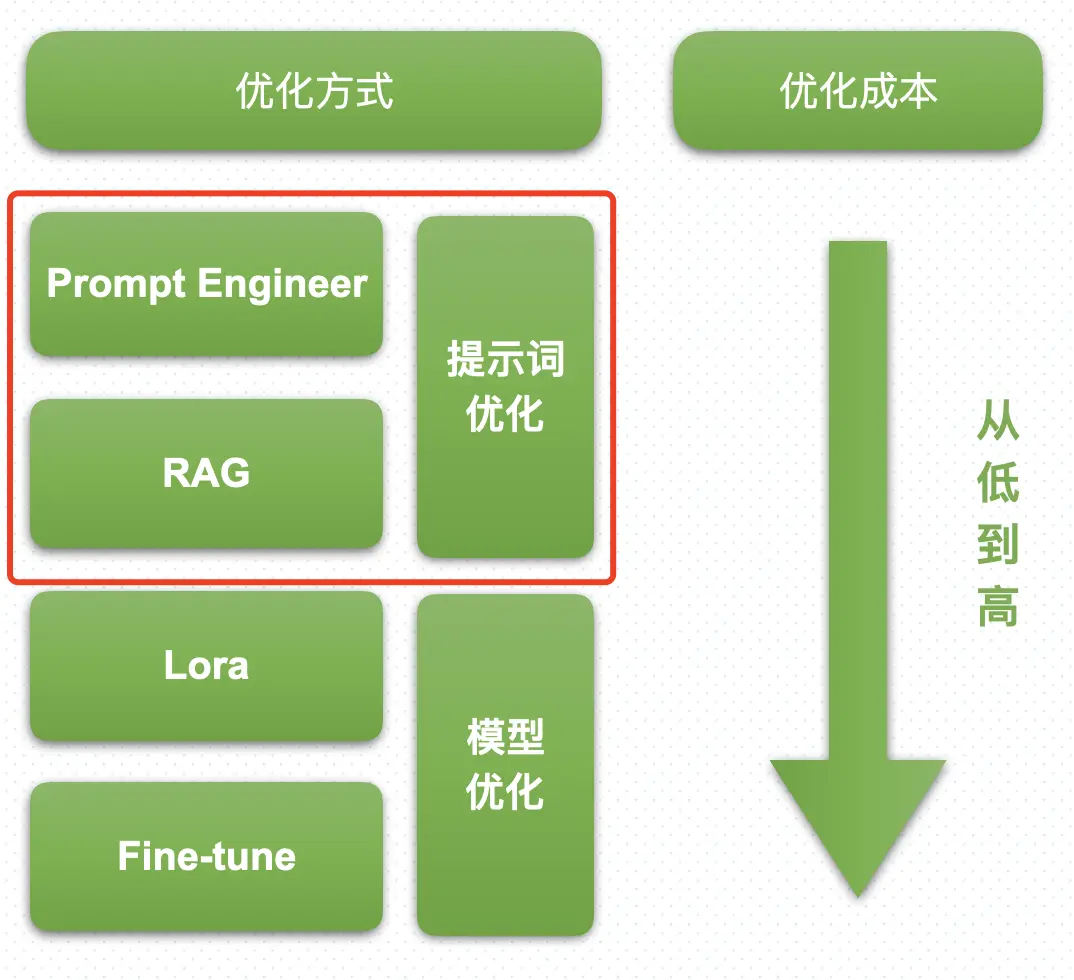
在技术架构上,后端用的是 Spring Boot,数据库用 MySQL 存储元数据,Redis 做缓存,Kafka 处理异步任务。前端是 Vue3 + TypeScript 的单页应用,界面比较现代化,用户体验还不错。
整个系统还支持实时对话功能,用户可以通过聊天的方式来查询知识,就像和一个智能助手对话一样。我们用 WebSocket 来实现实时通信,让交互更加流畅。
目前这个项目已经基本完成了核心功能的开发,包括文档上传、解析、向量化、检索等全流程。下一步我们计划优化搜索算法的准确性,还有就是增加更多的文档格式支持。
总的来说,这是一个结合了传统信息检索和现代 AI 技术的知识管理平台,尤其是 RAG 技术的应用,希望能够帮助企业/用户更高效地利用已有的知识资源。